Abstract
This thesis collects the outcomes of a Ph.D. course in Electronics, Telecommunications, and Information Technologies Engineering and it is focused on the study and design of techniques able to optimize resources in distributed mobile platforms.
It is related to a typical smart city environment, to enhance quality, performance and interactivity of urban services.
The subject is the operation of computation offloading, intended as the delegation of certain computing tasks to an external platform, such as a cloud or a cluster of devices. Offloading the computation tasks can effectively expand the usability of mobile devices beyond their physical limits and may be necessary due to limitations of a system handling a particular task on its own.
The computation offloading within an ecosystem as a urban community, where a large amount of users are connected towards even multiple devices, is a challenging subject. In a very close future, smart cities will be peculiar sources of intensive computing tasks, since they are conceived as systems where e-governance will be not only transparent and fast, but also oriented to energy and water conservation, efficient waste disposal, city automation, seamless facilities to travel and affordable access to health management systems. Also traffic will need to be monitored intelligently, emergencies foreseen and resolved quickly, homes and citizens provided with a wide series of control and security devices. All these ambitious aspirations will require the deployment of infrastructures and systems where devices will generate massive data and should be orchestrated in a collective way, to pursue synergic goals. In this context, the computation offloading is an operation dealing with the optimization of urban services, to reduce costs and consumption of resources and to improve contact between citizens and government.
This dissertation is organized in three main parts, dealing with the optimization of the resources in a smart city background from diffeerent points of view.
The first part introduces the Urban Mobile Cloud Computing (UMCC) framework, a system model that takes into account a series of features related to Heterogeneous Networks (HetNets), cloud architectures, various characteristics of the Smart Mobile Devices (SMDs) and different types of smart city application, performed to pursue several goals.
The second part deals with a partial offoading operation, considering to delegate only a portion of the computation load to a cloud infrastructure. It is focused on the tradeoff between energy consumption and execution time, in a non-trivial multi-objective optimization approach. Furthermore, a utility function model developed from the economic field is introduced. It takes into account a series of parameters related to the UMCC, showing that, when the network is overloaded, the partial offoading permits to achieve the target throughput values with an energy consumption and a computational time reduced, if compared with the total offoading of the computation tasks. In addition, the proposed UMCC framework and the partial computation offoading are applied to a vehicular environment for handling a real-time navigation application, so that the SMDs can exploit road side units and other neighbor devices forming clusters for delegating a shared application. It is shown that the clusterization allows to reduce the consumed energy in case of high traffic scenarios, optimizing the cluster size for different populations size and various offoading policies.
Finally, in the third part, the problem of Cell Association (CA) in a UMCC framework deals with the system as a community, thinking about to improve the collective performance and not only the achievement of a single device. A probabilistic algorithm that uses biased-randomization techniques is proposed as an efficient alternative to exact methods, which require unacceptable levels of computational time to solve real life instances. This probabilistic algorithm is able to provide near-optimal solutions in real time, thus outperforming by far the solutions provided by existing greedy heuristics. Since this algorithm takes into account all users in the assignment process, it avoids the selfish or myopic behavior of the greedy heuristic and, at the same time, is able to quickly find near-optimal solutions for allocation of the avaiable resources.
Introduction
According to the flagship publication of the United Nations World Urbanization Prospect, more than one half of the world population is living nowadays in urban areas, and about 70% will be city dwellers by 2050. Furthermore, the world population is estimated to increase in the second half of the 21st century, while the urban areas are expected to absorb all the predicted growth and to draw in some of the rural population. The United Nations report predicts that, by mid-century, there will be 27 megacities, with at least 10 million population, while at least half of the urban growth in the coming decades will occur in small cities with less than 500,000 people, envisioning therefore that cities, big or small, are becoming a determining shift in the organization of human society. Cities and megacities are predicted to magnify problems such as diffculty in waste management, scarcity of resources, air pollution, human health concerns, traffic congestion, and inadequate, deteriorating and aging infrastructures.
Concurrently with such urbanization effect, an extraordinary phenomenon concerning the Information and Communication Technology (ICT) is happening: smart mobile devices are becoming an essential part of human life and the most effective and convenient communication tools, not bounded in time and place. According to the Cisco Visual Networking Index, the number of mobile-connected devices has already overtaken the number of people in the world, and by 2018 it will be over 10 billion, including Machine to Machine (M2M) modules. Overall mobile data traffic is expected to have nearly an 11-fold increase in the next five years.
Urbanization tendency and smart mobile expansion are going to reach a relevant convergence point through the concept of smart city, an icon of a sustainable and livable city, projecting the ubiquitous and pervasive computing paradigms to urban spaces, focusing on developing city network infrastructures, optimizing traffic and transportation flows, lowering energy consumption and offering innovative services. It is through ICT that smart cities are truly turning smart [1], in particular by means of the exploitation of smart mobile devices, forming together with cloud computing the Mobile Cloud Computing (MCC), since, as suggested by Michael Batty, to understand cities we must view them not simply as places in space but as systems of networks and flows [2].
Original Contribution
In this dissertation, innovative techniques and methodologies aimed to enhance the performance of MCC applied to a smart city are proposed and investigated.
In particular the UMCC, a global framework that can be adapted depending on the optimization objectives introduced, highlighting the features that can affect the QoS of various types of smart city related applications.
Furthermore, various optimization techniques, based on opportunely defined cost or utility functions, are presented and inspected for the optimization of the resources in the UMCC.
Specifically:
- a partial offloading tecnique is determined for optimizing time and energy consumption in a smart city HetNets scenario, where smart mobile devices are supposed to perform a distributed application;
- a utility function model derived from the economic world has been presented, aiming to measure the QoS, in order to choose the best access point in a HetNet for offloading part of an application on the HetNets;
- a cluster-based optimization technique is proposed and utilized in a distributed computing resource allocation, exploiting resource sharing, in high density SMD environments.
During my Ph.D. course I had the opportunity to collaborate with the Internet Interdisciplinary Institute (IN3) at the Open University of Catalonia (UOC), where I contributed to develop new optimization heuristics for improving heterogeneous communication systems.
The applied approach is based on the use of biased randomization techniques, which have been used in the past to solve similar combinatorial optimization problems in the fields of logistics, transportation, and production.
This work extends their use to the field of smart cities and mobile telecommunications. Some numerical experiments contribute to illustrate the potential of the proposed approach. The outcomes of this research stay are described in Chapter 5.
Personal Publications
[p1] D. Mazza, D. Tarchi, and G. E. Corazza, "A Unified Urban Mobile Cloud Computing Offloading Mechanism for Smart Cities" Communication Magazine, IEEE (submitted) Go Back
[p2] available here - D. Mazza, A. Pages, D. Tarchi, A. Juan, and G. E. Corazza, "Supporting Mobile Cloud Computing in Smart Cities via Randomized Algorithms," Systems Journal, IEEE, DOI:10.1109/JSYST.2016.2578358. Go Back
[p3] available here - D. Mazza, D. Tarchi, and G. Corazza, "A cluster based computation offlooading technique for mobile cloud computing in a smart city scenario," in Proc. of IEEE Conference on Communication (ICC) 2016, Kuala Lumpur, Malaysia. Go Back
[p4] available here - D. Mazza, D. Tarchi, and G. E. Corazza, "A user-satisfaction based offloading technique for smart city applications," in Proc. of IEEE Globecom 2014, Austin, TX, USA, Dec. 2014. Go Back
[p5] available here - D. Mazza, D. Tarchi, and G. E. Corazza, "A partial offloading technique for wireless mobile cloud computing in smart cities," in Proc. of 2014 European Conference on Networks and Communications (EuCNC), Bologna, Italy, Jun. 2014. Go Back
Acknowledgments
This Ph.D. dissertation was carried out during three years of my life in which not only I have gained knowledge and accomplished an academic path, but also I have had the opportunity to proof and enrich my personality. I would like to thank Prof. Giovanni Emanuele Corazza and Prof. Daniele Tarchi for their precious advice and support during my Ph.D. studies. They helped me during every step of my work with unmatched competence and patience.
A sincere thanks goes to Prof. Ángel Alejandro Juan Pérez and Prof. Adela Páges Bernaus for giving me the chance to work with them at the DPCS IN3 Lab of the Open University of Catalonia: for their collaboration and for being always available to share projects and ideas and because my stay in Barcelona has been a unique experience for me, both professionally and personally.
I am also deeply grateful to Prof. Alessandro Vanelli Coralli, Coordinator of the Ph.D. Program in Electronics, Telecommunications, and Information Technologies, for making it possible to carry out this work.
A special acknowledgment goes also to all my colleagues that shared with me many important moments during my time at the University of Bologna - Roberta, Sergio, Vahid, Vincenzo - and at the Internet Interdisciplinary Institute IN3 in Barcelona - Aljoscha, Carlos, Jesica, Laura, Helena.
I also want to thank the reviewers of this thesis, Prof. Flavio Bonomi and Prof. Mohsen Guizani, for their many suggestions and help for greatly improving the quality of this work.
Infine, il piú grande ringraziamento va alla mia famiglia. Grazie a Gabriele, mio compagno di vita, per aver condiviso la mia esperienza e per avermi supportato e incoraggiato, ai miei genitori, per avermi infuso l'amore per lo studio e la ricerca, e a mio figlio Alessandro, che sempre mi ha dato la forza per continuare a dedicarmi alla ricerca.
Part I - Urban Mobile Cloud Computing: a framework at the service of smart cities
Innovative projects of smart cities, aiming to make effective a vision where cities can use technology to meet sustainability goals, boost local economies, and improve urban services, have been adopted in the political agenda of many governments as a primary program, in a large number of developed and developing countries. This development is in line with the evolutionary trends in the Information Society [3].
The ever-growing demand for services from citizens and institutions, intending to make the cities smarter and improve the quality of life of the communities, has given a great boost to the conception of diverse wireless communication systems and has extended the envision of cloud architectures for providing infrastructures (IaaS), platforms (PaaS), and software (SaaS) [4], [5], offering computation, storage and network and going towards the integration with novel opportunistic communications as fog networking [6], [7], [8].
In order to interact with city services, MCC and wireless HetNets contribute in different and sinergic way for handling this smart city scenario, allowing ubiquitous and pervasive computing in a framework we called UMCC.
In this first part of the dissertation, the proposed UMCC system model is described and investigated. It takes into account a series of features related to HetNet's nodes, cloud architectures, SMDs' characteristics, in association with several types of application and goals - mobility, healthcare, energy and waste management, and so on. It can be employed in the optimization of the QoS's requirements related to the needs of citizens.
Smart cities applications are gaining an increasing interest among administrations, citizens and technologists for their suitability in managing the everyday life. One of the major challenges is managing in an efficient way the presence of multiple applications in this UMCC framework, in a Wireless HetNet environment, alongside the presence of a MCC infrastructure.
The content of the following chapter was extracted from publications [P1], [P2] and [P3].
Chap. 1. The Urban Mobile Cloud Computing (UMCC) Architecture
1.1 Introduction to the UMCC in a smart city scenario
The increasing urbanization level of the world population has driven the development of technology toward the definition of a smart city geographic system, conceived as a wide area characterized by the presence of a multitude of smart devices, sensors and processing nodes aiming to distribute intelligence into the city; moreover, the pervasiveness of wireless technologies has led to the presence of heterogeneous networks operating simultaneously in the same city area. One of the main challenges in this context is to provide solutions able to optimize jointly the activities of data transfer, exploiting the heterogeneous networks, and data processing, by using different types of devices. In this chapter, the UMCC framework is introduced, considering a mobile cloud computing model that describes the flows of data and operations taking place in the smart city scenario.
The challenges and the opportunities of exploiting the UMCC are discussed in relation to smart city solutions, highlighting the features that can affect the QoS of various types of smart city related services.
The UMCC sprang from the MCC, that is gaining an increasing interest in the recent years, due to the possibility of exploiting both cloud computing and mobile devices for enabling a distributed cloud infrastructure [9].
Considering the peculiarity of the MCC, we can observe that, on one hand, the cloud computing idea has been introduced as a mean for allowing a remote computation, storage and management of information, and, on the other hand, the mobility skill allows to gain by the most modern smart devices and broadband connections for creating a distributed and flexible virtual environment.
At the same time, the recent advances in the wireless technologies are defining a novel pervasive scenario where several heterogeneous wireless networks interact among them, giving the users the ability to select the best network among those present in a certain area.
As a consequence, the development of the UMCC is introduced, gaining from both computing and wireless communication technologies. It is a challenging opportunity for the creation of smart city infrastructures, providing solutions fulfilling the urgent need for richer application and services, requested from citizens that, as mobile users, are facing many demanding tasks in relation to mobile device resources as battery life, storage and bandwidth.
The triple role of Smart Mobile Devices
By analyzing the technology systems underlying a smart city framework, mobile devices can be considered in a three-fold way, as illustrated in fig.1:
- Sensors
They can acquire different types of data regarding the users and the environment, transmitting a large amount of information to the cloud in real time, by means of wireless communication systems. This is the underlying concept of IoT, profitably exploited to improve urban life, for instance for extracting descriptive and predictive models in the urban context of cities [10]. As well as the expansion of Internet-connected automation into a plethora of new application areas, IoT is also expected to generate large amounts of data from diverse locations, with the consequent necessity for quick aggregation of the data, and an increase in the need to index, store, and process such data more effectively. - Nodes:
They can form distributed mobile clouds where the neighboring mobile devices are merged for resource sharing, becoming integral part of the network. Furthermore, they can form VCNs offering content routing, security, privacy, monitoring, virtualization services [11], easy to be used for providing smart city services and applications, in particular for traffic and mobility control. This is the crucial concept of fog networking, where a collaborative multitude of users carry out a substantial amount of storage, communication, and data management in a collaborative way. - Outputs:
They can make the citizens aware of results and able to decide consequently, or become actuators without need of human intervention. This is the concept underlying M2M communications where computers, embedded processors, smart sensors, actuators and mobile devices acquire information and act in an autonomous way [12].
To perform this triple role, mobile devices have to become part of an infrastructure that is constituted by different cloud topologies and, at the same time, have to exploit heterogeneous wireless link technologies, allowing to address the different requirements of a smart city scenario. This infrastructure starts from the concept of MCC, where the cloud works as a powerful complement to resource-constrained mobile devices.

The vision of MCC has increasingly become a source of interest, beginning from the early 2000s, when Amazon realized that a huge amount of space on their premises was underused. This awareness pushed toward the implementation of remote services, gaining by the presence of storage space and computing power and creating a cloud system. Alongside with the expansion of wireless technologies, the cloud computing has been integrated through a broadband system, exploiting the opportunity of working in mobility. The SMDs, then, can use MCC devolving demanding tasks and referring to it for data storage.
Computation Offloading
The strategy allowing to delegate to one or more cloud computing elements storage and computing functions is commonly called cyberforaging or computation offloading. It allows to tackle with the limited battery power and computation capacity of the SMDs, and plays a key role in a smart environment where wireless communication is of utmost relevance, particularly in mobility and traffic control domains [13]. If the storage is one of the most common and legacy activities that can be delegated to a remote cloud infrastructure, recently, thanks to modern programming paradigms, it is possible to allot even only a part of the computation load to a remote unit. This allows users to optimize the system performance by offloading only a fraction of the application to be computed, or distributing the application among different cloud structures. Offloading is an effective network congestion reduction strategy to solve the overload issue compared to scaling and optimization [14]. It enables network operators to reduce the congestion in the cellular networks, while for the end-user it provides cost savings on data services and higher bandwidth availability.
1.2 Cloud Topologies
In relation to the SMD's roles previous described, we take into account various cloud topologies. This is a different categorization with respect to the common taxonomy used for cloud computing - SaaS, PaaS and IaaS. It looks on the different interaction among the nodes that form the cloud, instead of the services provided by the cloud itself, so we can distinguish among centralized cloud, cloudlet, distributed mobile cloud and a combination of all, as shown in fig 2.

Centralized Cloud
A centralized cloud provides the citizens to interact remotely, e.g., for accessing to open data delivered by the public administrations. It refers to the presence of a remote cloud computing infrastructure having a huge amount of storage space and computing power, virtually infinite, offering the major advantage of the elasticity of resource provisioning. The centralized cloud infrastructure is often used for delivering the computing processes to remote clusters, owing a higher computing power, and/or for storing big amount of data. The centralized cloud allows to reduce the computing time by exploiting powerful processing units, but it could suffer from the distribution latency, due to the data transfer from the users to the cloud and vice versa, the congestion, due to the multiple users exploitations, and the resiliency, due to the presence of a single performing infrastructure leading to the SPOF issue.
Cloudlet
One of the main drawback of the centralized cloud is the great distance between the mobile devices, requesting services, and the clusters, performing computation in the cloud. Even if the SPOF issue is often resolved by implementing mirroring or redundancy solutions, the big distance that may occur between users and centralized clouds can be better addressed by means of the introduction of cloudlets, representing small clouds installed in proximity of the users. Furthermore, the inclusion of cloudlets allows a most appropriate sizing depending on the number of contemporary requests of the users.
Cloudlets are fixed small cloud infrastructures installed between the mobile devices and the centralized cloud, limiting their exploitation to the users in a specific area. Their introduction allows to decrease the latency of the access to cloud services by reducing the transfer distance at the cost of using smaller and less powerful cloud devices.
Distributed Mobile Cloud
A third configuration can address the issue of non persistent connectivity, whereas both the previous concepts must assume a durable state of connection. In a distributed mobile cloud the neighboring mobile devices are pooled together for resource sharing [15]. An application from a mobile device can be either processed in a distributed and collaborative fashion on all the mobile devices or handled by a particular mobile device that acts as a server.
The possibility of implementing a distributed mobile cloud infrastructure has become a reality since the introduction of smarter and powerful mobile devices, e.g., smartphones, tablet, phablet, having the ability, even if limited, of computing and storaging. Moreover, it has to be noted that their number is still increasing, leading to a pervasive presence and allowing to form a cloud of pervasive distributed devices that can interact among them. This fog network architecture uses one or a collaborative multitude of end-user clients or near-user edge devices to carry out a substantial amount of storage (rather than stored in centralized clouds), communication, and control, configuration, measurement and management [7], [8]. It can be seen as the fog layer that encapsulates phisical objects - equipped with computing, storage, networking, sensing, and/or actuating resources - and constitutes a piece of a wider CARS architecture [16], a geographically distributed platform that connects many billions of sensors and things, and provides multitier layers of abstraction of sensors and sensor networks, enabling the SenaaS.
Combination of different topologies
The proposed framework foresees the joint exploitation of the three aforementioned topologies. As outlined before, they are characterized by different features, leading to a different usage depending on the scenario. Hence, a joint exploitation could steer to a more efficient usage aiming to achieve the performance goals of a certain application. As it will be better specified below, a smart city scenario is characterized by the presence of a lot of different applications, each one with different characteristics and requirements. An integrated UMCC framework composed by centralized clouds, cloudlets and distributed mobile clouds, as shown in fig 2, allows to respect the application requirements with regard to other solution in a more efficient way.
1.3 Types of RATs
In order to connect the devices, different types of RATs should be taken into consideration, providing a pervasive wireless coverage.
Multiple RATs, such as IEEE 802.11, mobile WiMAX, HSPA+, LTE and WiFi, have to be integrated to form a HetNet. For enhancing the network capacity, generally there is an increasing interest in deploying relays, distributed antennas and small cellular base stations - picocells, femtocells, etc - indoors in residential homes and offices as well as outdoors in amusement parks and busy intersections. These new network deployments, comprised of a mix of low-power nodes underlying the conventional homogeneous macrocell network, by deploying additional small cells within the local-area range and bringing the network closer to users, can significantly boost the overall network capacity through a better spatial resource reuse. Inspired by the attractive features and potential advantages of HetNets, their development have gained much momentum in the wireless industry and research communities during the past few years. The heterogeneous elements are distinguished by their transmit powers/coverage areas, physical size, backhaul, and propagation characteristics.
We can basically distinguish between two components, i.e., macrocells and small cells, where the former provide mobility while the latter boost coverage and capacity.
Macrocells
The distance between the access points (base stations of the macrocells) is usually higher than 500~m. Thanks to this type of base stations the environment is completely covered and the devices can move by minimizing the handover frequency. On the other hand, in macrocells the system suffers for channel fading and traffic congestion. This leads to a lack of stability, not allowing to reach very high data rate. The technology used for this type of cells refers to the cellular networks, e.g. 3G and LTE.
Small Cells
Small cells are characterized by low power radio access nodes, which have a cover range of about 100-200~m or less. We can distinguish between picocells, for providing hotspot coverage in public places - malls, airports and stadiums - without limits in terms of number of connected devices, and femtocells, for covering a home or small business area, available only for selected devices. Picocells and femtocells have been recently introduced as a way for increasing the coverage and maximize the resource allocation in LTE networks. We also consider WiFi access points as nodes with a small cover range (less than 100 m) which can typically communicate with a small number of client devices. However, the actual range of communication can vary significantly, depending on such variables as indoor or outdoor placement, the current weather, operating radio frequency, and the power output of devices.
1.4 Challenges of the UMCC
The UMCC approach foresees the definition of a scenario where smart city applications can exploit jointly the three topologies, as shown in fig.3, by distributing and performing among the different parts composing the framework. The application requested by a particular SMD, signed as the RSMD, is partitioned and distributed among the different clouds using the available RATs. In the example of fig.3, the application is divided among the centralized cloud, two cloudlets, and a distributed cloud formed by five devices. Furthermore, part of the application can be computed locally by the RSMD itself.
The main issue is that, for transferring data from the requesting mobile device to the selected cloud topology, a certain time is required. This mostly depends on some communication parameters of the selected RAT, such as the end-to-end throughput, the amount of users, the QoS management of a certain transmission technology between the user device and each type of cloud processing unit. Furthermore, in terms of energy consumption, it should be taken into account the tradeoff between the energy saved in offloading part of the application to the cloud and the energy spent in sending the data.

Hence, when a RSMD needs to select the clouds infrastructures to be used for computing the smart city application, two main elements have to be taken into account:
- the processing and storage devices - smart mobiles, per se or together forming distributed mobile clouds, and cloud servers, constituting the cloudlets and the centralized cloud;
- the wireless transmission equipments, - different RAT nodes entailing diverse transmission speeds in relation to their own channel capacity and to the number of linked devices.
In fig.3, the UMCC framework is sketched by representing the functional flows of the architecture. Whenever a smart city application should be performed, the citizen within the UMCC can select among different MCC infrastructures, i.e., centralized clouds, cloudlets, and distributed mobile clouds, aiming to respect the requirements of the specific application depending on their features. The distribution depends on the application requirements, and the UMCC features; its optimization will be discussed in the Section 1.7.
Computation, storage, and tranmission features
The features of the selected processing and storage devices, considered per se or in a group forming cloud/cloudlets, are:
- Processing Speed: The processing speed corresponds to the performance speed of a device or a group of devices for processing the applications;
- Storage Capacity: The storage capacity corresponds to the amount of storage space provided by a device or a group of devices.
In the same time, the features of the transmission equipments to be taken into account are:
- Channel Capacity: The nominal bandwidth of a certain communication technology that can be accessed by a certain device;
- Priority/QoS management: The ability of a certain communication technology to manage different QoS and/or priority levels;
- Communication interfaces: The number of communication interfaces of each device, that impacts on the possibility of selection among the available heterogeneous networks.
1.5 The UMCC model
In this paragraph we focus on the different entities playing a role in the UMCC framework, describing the functions and the interactions among them. First of all, we are focusing on an application ${App}$ requested by a RSMD, defined through the number of operation to be executed, $O$, the amount of data to be exchanged, $D$, and the amount of data to be stored, $S$. An application can be seen as a smart city service, that can be executed either locally or remotely by exploiting the cloud infrastructures. Furthermore, each application has many requirements regarding the levels of QoS. We have taken into account the following:
- the maximum accepted latency $T_\textit{app}$, intended as the interval between the request of performing an application and the acquisition of its results by the RSMD,
- the minimum level of energy consumption $E_\textit{app}$, that the RSMD necessarily uses for performing the application itself,
- the throughput $\eta_\textit{app}$, intended as the minimum bandwidth that the application needs for being performed.
Hence, for highlighting the $\textit{App}$ dependence from the above measures, we can write:
\begin{equation} App = App(O,D,S,T_\textit{app},E_\textit{app},\eta_\textit{app}) \tag{1.1} \end{equation}A foundamental entity acting in the system is the RSMD requesting the $\textit{App}$, we named $\textit{Dev}$, characterized by certain features that are involved in the offloading operation: the power to compute applications locally, $P_l$, the power used for transferring data towards clouds, $P_{\textit{tr}}$, the power for idling during the computation in the cloud, $P_{\textit{id}}$, the computing speed to perform locally the computation, $f_{\textit{l}}$, and the storage availability, $H_{\textit{l}}$. Furthermore, also the time-varying position of the device plays an important role in the system interactions. Hence, we can write:
\begin{equation} Dev = Dev(P_l, P_{\textit{tr}}, P_{\textit{id}}, f_{\textit{l}}, H_{l}, pos_{\textit{dev}}(x, y)) \tag{1.2} \label{eq:Dev} \end{equation}Focusing on the different types of cloud entities in our scenario, we considered a unique centralized cloud $C_{\textit{cc}}$ and various cloudlets $C_{\textit{cl}}$ characterized by their own computing speed to perform the computation, i.e., $f_\textit{cc}$ for the centralized cloud and $f_\textit{cl}$ for the cloudlets. Additionally, the storage availability $H_\textit{cl}$ of each cloudlet has to be taken in consideration, while the storage availability of the centralized cloud can be considered infinite, therefore not constraining in the interaction. Hence, we can write for the centralized cloud $C_{\textit{cc}}$:
\begin{equation} \label{eq:Ccc} C_{\textit{cc}} = C_{\textit{cc}}(f_{\textit{cc}}) \tag{1.3} \end{equation}and for each cloudlet, considering also the influence of the position $pos_\textit{cl}(x, y)$ of the in-built AP, the end-to-end throughput $\eta_{\textit{cl}}$ provided by the AP itself, the maximum number of devices that it is possible to connect at the same time $n_\textit{cl}$, and the range of action $ r_{\textit{cl}}$:
\begin{equation} \label{eq:Ccl} C_{\textit{cl}} = C_{\textit{cl}}(f_{\textit{cl}}, H_{\textit{cl}}, pos_{\textit{cl}}(x, y), \eta_{\textit{cl}}, n_\textit{cl}, r_{\textit{cl}}) \tag{1.4} \end{equation} We are considering the system from the point of view of a single RSMD requesting to run an application, while the set of the other SMDs constituting the distributed cloud are providing a service for supporting the RSMD. Thus, the distributed cloud is a set of generic entities $\textit{MD}s$, each characterized by its specific connectivity, computation and storage for the exchange of data, i.e. the computing speed $f_{\textit{MD}}$, the storage availability $H_{\textit{MD}}$, the position $pos_{\textit{MD}}(x, y)$, the throughput $\eta_{\textit{MD}}$, the number of devices that can be connected to each device$n_{\textit{MD}}$, and each range of action $r_{\textit{MD}}$. Thus, we can write for the generic device $\textit{MD}$: \begin{equation} \label{eq:SMD} \textit{MD} = \textit{MD}( f_{\textit{MD}}, H_{\textit{MD}}, pos_{\textit{MD}}(x, y), \eta_{\textit{MD}} , n_{\textit{MD}}, r_{\textit{MD}} ) \tag{1.5} \end{equation}While the connection to the cloudlets can be made only through the unique AP that can be considered built-in in each cloudlet itself, and the connection of the distributed cloud to the RSMD can be made directly, the nodes of the HetNet offer different choices to connect towards the centralized cloud. Thus, for each involved node $\textit{Nod}$ constituting the centralized cloud, specifying that $pos_\textit{Nod}(x,y)$ is the position of the node, $\eta_\textit{Nod}$ is the end-to-end throughput in bit per second between the user and the exploited node, $n_\textit{Nod}$ is the number of devices available to connect, and $r_\textit{Nod}$ is the range of availability of the node, we can write:
\begin{equation} \label{eq:Nod} \textit{Nod} = \textit{Nod}(pos_{\textit{Nod}}(x, y), \eta_{\text{Nod}} , n_{\text{Nod}}, r_{\text{Nod}}) \tag{1.6} \end{equation}The Tab 1.1 summarizes the entities and the characteristics above described.
Tab 1.1 - Summary of smart city applications and requirements.

They are in a certain relationship due to some physical and logical constraints derived from the following considerations.
First, for distributing the computation of the application among the different types of clouds, the system has to evaluate which HetNet nodes, cloudlets, and SMDs are available. The availability is realized if the RSMD is in the range of action of a particular HetNet node, cloudlet or SMD and if these entities are not busy, i.e., if the number of devices connected to an entity $n_\text{conn}$ is less than $n_\textit{Nod}$, $n_\textit{cl}$, or $n_\textit{MD}$, dependently from the type of entity.
Thus, there are $M$ available HetNet nodes $\textit{Nod}$ for offloading towards the centralized cloud, $N$ cloudlets $C_{\textit{cl}}$ and $K$ devices $\textit{MD}$, able to share the computation in the distributed cloud. After the detection of the available entities (which are a total of $1+M+N+K$, including the local node RSMD, which we consider for simplicity the node of index 0), the next step is to distribute, by means of all these entities, different percentages $\alpha_i$ of operations $O$, $\beta_i$ of data $D$, and $\gamma_i$ of memory $S$, to all the available nodes, cloudlets and devices, under the constraints:
\begin{equation} \label{eq:alpha} \sum_{i=0}^\textit{M+N+K} \alpha_i = 1 \tag{1.7} \end{equation}and
\begin{equation} \label{eq:beta} \sum_{i=1}^\textit{M+N+K} \beta_i = 1 \tag{1.8} \end{equation}Alongside the computing capacity, it is possible to define a constraint regarding the storage availability of the cloudlets and the SMDs by means of the following equations, considering infinite the storage availability of the centralized cloud:
\begin{equation} \label{eq:storage} \gamma_i S \le H_i \quad \quad \forall i \in \{0,1,...,i,..., \textit{N+K}\} \tag{1.9} \end{equation}that stands for an upper limit of remotely used storage of a certain $i$-th cloud infrastructure.
A constraint related to the application's requirements $\eta_\textit{app}$ involves the throughput of the entities designated for the offloading: the overall throughput offered by the selected devices should be higher than the minimum throughput requirement of a certain application:
\begin{equation} \label{eq:throughput} \sum_{i=1}^\textit{M+N+K} \eta_i \ge \eta_\textit{app} \tag{1.10} \end{equation}From the point of view of the RSMD, the energy spent for offloading the application can be written as the sum of the energy spent to perform locally a part of the task, plus the energy spent by the RSMD for the transmission of data to the clouds, plus the energy spent during the idle period when the computation is being offloaded. Hence, the restriction related to the requirement $E_\textit{app}$ leads to the following:
\begin{equation} \label{eq:energy} P_l \frac{\alpha_0 O}{f_l} + \sum_{i=1}^\textit{M+N+K}{P_\textit{tr}\frac{ \beta_i D}{\eta_i} + P_\textit{id} \operatorname*{arg\,max}_{i =1,\textit{M+N+K}}\left \{ \frac{\alpha_i O }{f_i} \right \}}\le{E_\textit{app}} \tag{1.11} \end{equation}In the same time, the total latency is the sum of the time for computing locally the $\alpha_0$ percentage of computation, plus the times to transmit/receive data to/from the other computation units, plus the maximum of the time to compute in offloading. Hence, the restriction related to the requirement $T_\textit{app}$ leads to the following:
\begin{equation} \label{eq:latency} T=t_l^{\text{comp}}+t_{cc}^{\text{tr}}+t_{cc}^{\text{comp}}+t_{cl_j}^{\text{tr}}+t_{cl}^{\text{comp}}+t_{dc_j}^{\text{tr}}+t_{dc}^{\text{comp}}\\ \alpha_0 \frac{O}{f_l}+ \sum_{i=1}^\textit{M+N+K} \frac{ \beta_i D}{\eta_i} + \operatorname*{arg\,max}_{i =1,\textit{M+N+K}}\left \{ \frac{\alpha_i O }{f_i} \right \}\le{T_\textit{app}} \tag{1.12} \end{equation}Furthermore, the throughput $\eta_i$ is related to the number of devices $n_i$ connected to the $i^{th}$ entity and the channel capacity $BW_i$ as shown by the following representing the Shannon Formula:
\begin{equation} \eta_i = \frac{\textit{BW}_i}{n_i}\cdot \log_2{\left(1+\frac{\textit{SNR}_i}{d_i^2}\right)} \tag{1.13} \label{eq:shannon1} \end{equation}where $\textit{SNR}_i$ is the SNR of the related link and $d_i$ the distance between the receiver and the transmitter. Thus, the optimization of the system consists in finding the values of $\alpha_i$, $\beta_i$ and $\gamma_i$ that satisfy eqs.\eqref{eq:alpha}-(\ref{eq:shannon1}). This is a nontrivial optimization problem, but the complexity can be decreased with the introduction of some simplifications, as presented in the following chapters.
1.6 Requirements of smart city applications
There are many taxonomies trying to define smart city key areas, where social aims, care for environment, and economic issues are related and interconnected. The European Research Cluster on the Internet of Things (IERC) has identified in [17] a list of applications in different domains of IoT, including the smart city domain, showing the utmost strategic technology trends for the next five years. Moreover, the Net!Works European Technology Platform for Communications Networks and Services has issued a white paper [18] aiming to identify the major topics of smart cities that will influence the ICT environment. Furthermore, a relevant document aiming to categorize and define the different applications has been released by European Telecommunications Standards Institute (ETSI), where several application types have been specified focusing on their bandwidth requirements [19].
Taking into account all the relevant observations presented in these essays, we analyzed some particular smart city applications covering the areas of mobility, healthcare, disaster recovery, energy, waste management and tourism, in order to leverage the UMCC identifying the requirements which are related to the QoS.
Each application is defined through the service provided to the citizens, concerning the requirements in terms of throughput, energy consumption, time due to the transferring and computation processes, and number of users. In addition, for every application, the typical requirements of processing, data to exchange and storage have been established. The following list summarizes the definition of these requirements:
- Latency: The latency is defined as the amount of time required by a certain application between the event happens and the event is acquired by the system;
- Energy Consumption: The energy consumption corresponds to the energy consumed for executing a certain application locally or remotely;
- Throughput: The throughput corresponds to the amount of bandwidth required by a specific application to be reliably installed in the smart city environment;
- Computing: The computing corresponds to the amount of computing process requested by a certain application;
- Exchanged data: The exchanged data correspond to the amount of input, output and code information to be transferred by means of the wireless network;
- Storage: The storage corresponds to the amount of storage space required for storing the sensed data and/or the processing application;
- Users: The users correspond to the number of users for achieving a reliable service.
The QoS is a function of the previous requirements, where each one of these plays a role less or more important depending on the aims of the application. In the following list the considered application types are described by highlighting their technological requirements and characteristics, while in Tab 1.2 the considered application types and the significance of their requirements are summarized.
| Application | latency | energy | throughput | computing | exchanged data | storage | users |
|---|---|---|---|---|---|---|---|
| Mobility | restrictive | variable | restrictive | high | high | variable | high |
| Healthcare | restrictive | non-restrictive | restrictive | high | high | high | low |
| Disaster Recovery | restrictive | restrictive | non-restrictive | high | high | high | variable |
| Energy | non-restrictive | non-restrictive | non-restrictive | high | high | high | high |
| Waste Management | non-restrictive | restrictive | non-restrictive | low | low | low | low |
| Tourism | non-restrictive | restrictive | non-restrictive | high | high | high | variable |
Mobility
All the components in an intelligent transportation system could be connected to improve transportation safety, relieve traffic congestion, reduce air pollution and enhance comfort of driving. The three-layered hierarchical cloud architecture for vehicular networks proposed by Yu et al. [20], where vehicles are mobile nodes that exploit cloud resources and services, can be considered as included in the UMCC framework. A real-time navigation with computation resource sharing, where the computation resources in the central cloud are utilized for data traffic mining, requests a minimal latency, since a ready response is needed. On the other hand, considering that the great part of mobile devices can be recharged directly from the car, energy consumption has to be considered only for pedestrians and bicycles. The necessary throughput, the computational load and the amount of data to exchange are high, whereas we can think the storage as a secondary requirement, unless for security recording.
Healthcare
Intelligent and connected medical devices, monitoring physical activity and providing efficient therapy management by using patients' personal devices, could be connected to medical archives and provide information for medical diagnosis. We considered in the UMCC framework the typical architecture proposed by He et al. [21], requiring a full integration of the clinical devices and efficient processing of the collected data, considering, for instance, a cloudlet nearby the home of the patient. In this case there are relatively low requirements regarding energy consumption, throughput and number of users, whereas the requirements of latency, computation, exchanged data and storage are high, considering the complexity of the management algorithm, the video monitoring for remote diagnosis and the data to store for the personal record archive.
Disaster Recovery
In [22] a disaster relief scenario is described, where people are facing with the destruction of the infrastructures and local citizens are asked to use their mobile phones to photograph the site. Also this case introduces the three-layered cloud described in the UMCC framework, requiring to transmit a lot of data using the cameras provided by the smartphones to reconstruct the disaster scene. In this case there are relatively low requirements regarding throughput, whereas it is important to have a quick response and to save the energy of the devices. There are a lot of computation to reconstruct the scene and a lot of data to exchange and to store. The number of users is variable.
Energy
Energy saving can take advantage from the cloud basically thanks to smart grid systems, aimed to transform the behavior of individuals and communities towards a more efficient and greener use of electric power. Data fusion and mining, as well as scheduling and optimization, are critical in order to include the use of wireless communications to collect and exchange information about electric quality, consumption, and pricing in a secure and reliable fashion. By analyzing the specific aspects regarding the UMCC, if we consider an application where vehicles are involved in a smart grid system, we can suppose that a big data exchange is needed, there is a lot of computation and storage between a large number of users, whereas there are relatively low requirements regarding latency and throughput, and energy saving is not a problem for the devices involved.
Waste Management
Automatically generated schedules and optimized routes which take into account an extensive set of parameters (future fill-level projections, truck availability, traffic information, road restrictions, etc.) could be planned not only looking at the current situation, but also considering the future outlook. A logistic solution that uses wireless sensors to measure and forecast the fill-level of waste and recycling containers could combine fill-level forecasts with an extensive set of collection parameters (e.g., traffic information, vehicle information, road restrictions) in order to calculate the most cost efficient collection plan. This smart plan would be automatically generated and accessed by the driver through a tablet (Example from www.enevo.com). We can expect non-restrictive requirements of latency and throughput, whereas resource-poor equipments have to be taken into consideration. The requirements related to data to be exchanged, load of computation, storage and number of users are not critical.
Tourism
Augmented reality and social networks are the characteristics of applications that more take advantage from the cloud, that becomes also useful for mobile users sharing photos and video clips, tagging their friends in popular social networks like Twitter and Facebook. The cloud is effective also when mobile users require searching services, also using recognition techniques (using voice, images and keywords - example from www.mtrip.com/augmented-reality/. We can expect not-restrictive requirements of latency and throughput, whereas resource-poor equipments have to be taken into consideration. There are a great amount of data to be exchanged, load of computation and storage and number of users are variable.
1.7 A utility based resource optimization approach
The requirements related to the applications, and the associated QoS, can be respected by optimizing the application partitioning and node/cloud association based on the features of the processing and storage devices and of the transmission equipments introduced in section 1.4. Moreover, it should be noted that there is a correlation among the application requirements and the features of the UMCC equipments.
The latency suffered to perform a certain application can be seen as composed by the time needed for transferring the application data to the cloud computing infrastructure and the time needed for the cloud computation, therefore it is affected by the processing speed of the involved devices and by the channel capacity and the communication interfaces of the chosen transmission equipments. Furthermore, the energy spent to perform an application depends on the time needed for the data transfer, thus it depends on the channel capacity and the number of communication interfaces of the communication equipments; it has to be noticed that we have to consider also the energy spent by the user device while idles during the cloud computation, so that the processing speeds of the cloud devices are involved. The storage value of the application does not influence directly the performance of the system, but it can represent a limitation for the usability of a certain cloud infrastructure, as well as the number of potential users of the application.
A feasible optimization regarding the computing and the exchanged data requirements can be performed by operating on the complexity of the computability resources, considering also that, in partial offloading, the exchanged data could not be a predetermined value [23].
In this context, a utility function aiming to optimize the application-dependent QoS is proposed, acting as input for a procedure of partition and a node/cloud association, as shown in \ref{fig:FunctionalBlocks}. The utility function can be written as:
\begin{equation} U = \sum_{i=1}^{N_{req}}\gamma_i f_i(\xi_i) \label{eq:global-utility} \tag{1.14} \end{equation}where $N_{req}$ is the number of requirements for a certain smart city application, $\xi_i$ stands for the $i$-th application requirement among those defined in \autoref{sec:requirements}, and $\gamma_i$ is a weight value, while $f_i(\cdot)$ corresponds to a specific utility function used for evaluate the respect of the $i$-th requirement.
In Fig. 4, the functional blocks of the UMCC framework, based on a utility function optimization, are represented. On one hand, the smart city applications define specific requirements, while the cloud topologies in a certain scenario set their features. The utility function aims at selecting those cloud topologies that allow to respect the requirements by setting an optimized distribution of the application itself. The optimization of the partition and the node association will impact again on the UMCC features to be used by the other applications.

The maximization of the introduced utility function could be a nontrivial optimization problem, depending on the considered number of applications and devices acting in the selected scenario. In relation to the introduced requirements, the number of constraints could be reduced, and the complexity of the problem decreased by introducing opportunely defined sub-optimal solutions. All the utility and cost functions presented in the following chapters are particular cases of eq. \ref{eq:global-utility}. In particular, in chapter 2 a cost function including the tradeoff between energy consumption of mobile devices versus the time to offloading data and to compute tasks on a centralized remote cloud server is provided, evaluating the optimal offloading fraction depending on the network’s load; in chapter 3 and in chapter 5 we focused on a utility function representing the QoS degree perceived by the user, modeled as a sigmoid curve, that is a well-known function often used to describe QoS perception [24]; finally, in chapter 4, we focused on the computation offloading towards the distributed cloud, for offloading a real-time navigation application in a distributed fashion, aiming to minimize the execution time, since the devices are autonomous regarding the energy provision.
1.8 Conclusions
In this chapter we introduced the UMCC framework, a concept that supports the smart city vision for the optimization of the QoS of various types of smart city applications. The UMCC consists of different topologies of cloud and diverse types of RATs, that are used for offloading computation and share resources among the mobile devices. The QoS depends on the type of application, since it is affected by the defined requirements in a different way depending on the aims of the application itself. A cost function optimization approach is proposed, aiming to select the optimal partition level of the applications and the cloud infrastructures to be used for their computation. The optimization of the QoS is influenced by a big number of features, related to the choice of the distribution of data in the cloud units and the nodes used for the transmission, but the problem can be restricted considering some simplifications suggested by the aims and the domain of the application.
Part II - Partial Offloading Optimization
A UMCC framework settled on an efficient wireless network allows users to benefit from multimedia services in an ubiquitous, seamless and interoperable way. In this context MCC and HetNets are viewed as infrastructures providing together a key solution for the major facing problems: the former allows to offload application to powerful remote servers, shortening execution time and extending battery life of mobile devices, while the latter allows the use of small cells in addition to macrocells, exploiting high-speed and stable connectivity in an ever grown mobile traffic trend. In order to fulfill the computation offloading efficiently, in the following chapters we explore techniques aiming to move the computing application towards the cloud, considering a non-trivial multi-objective optimization approach that takes into consideration the tradeoff between the energy consumption of the SMDs and the time for executing the application. The aim of the optimization is to find the percentage of application offloading that minimizes the proposed cost function, in such a way that only a part of the application is transfered and computed outside, whereas the rest of the application is computed locally.
The chapter 2 deals with the partial offloading technique in a centralized cloud scenario. The results show that exists a particular offloading percentage value fitting the system in case of simultaneously high data and network workload, differently from the simple yes/no offloading decision which would move the entire application or would perform it locally. In chapter 3 the partial offloading technique is applied using a utility function model arising from the economic world. It aims to measure the QoS, in order to choose the best AP in a HetNet for running the partial computation offloading. The goal is to save energy for the SMDs and to reduce computational time. In chapter 4 the proposed UMCC framework and the partial computation offloading are applied to a vehicular environment for handling a real-time navigation application. In this case, we consider also cloudlets and distributed clouds, so that the SMDs can exploit road side units and other neighbor devices for delegating a shared application.
The content of the following chapters was extracted from publications [P3],[P4], and [P5].
A Partial Computation Offloading Technique
Introduction
Smart cities are considered a paradigm where wireless communication is an enhancing factor to make better urban services and improve the quality of life for citizens and visitors. In a smart city scenario several entities should be taken into consideration: the wireless infrastructure that allows data-exchange, the user devices, the sensing nodes, the machine devices, access points, one or more cloud infrastructures. Moreover, for delivering the requested services lots of data are exchanged among the citizens and the devices, and these data need also to be elaborated in order to give the correct information to the users. Thanks to various wireless communication technologies, users can move through different environments, indoor and outdoor, providing data to the cloud and receiving access services as browsing, video on demand, video streaming, information about location and maps. In this context, energy saving and performance improvement of the SMDs have been widely recognized as primary issues. In fact, the execution of every complex application is a big challenge due to the limited battery power and computation capacity of the mobile devices, especially in a smart environment where communication is considered a key to get better features in important areas such as mobility and transportation.
The exploitation of HetNet infrastructures together with the opportunity to delegate computation load to MCC, as shown in fig. 2.1, is an appealing connection achieving the aims of saving the SMD's power resource and executing the requested tasks in a faster way [23].
HetNets involve multiple types of low power radio access nodes in addition to the traditional macrocell nodes in a wireless network, reaching the major goal to enhance connectivity. On the other hand, MCC aims to increase the computing capabilities of mobile devices, to conserve local resources - especially battery charge - to extend storage capacity and to enhance data safety for making the computing experience of mobile users better [25] .
The distributed execution (i.e., computation/code offloading) between the cloud and mobile devices has been widely investigated [9], highlighting the challenges towards a more efficient cloud-based offloading framework and also suggesting some opportunities that may be exploited. Indeed, the joint optimization of HetNets and distributed processing is a promising research trend [5] .
Several works have already analyzed characteristics and capacity of MCC offloading, for example aiming to extract offloading friendly parts of codes from existing applications [26], [27]. Also, in [28] the key issues are identified when developing new applications which can effectively leverage cloud resources. Furthermore, in [29] a real-life scenarios, where each device is associated to a software clone on the cloud, has been considered, and in [30] a system that effectively accounts for the power usage of all of the primary hardware subsystems on the phone has been implemented, distinguishing between CPU, display, graphics, GPS, audio, and microphone.
In [31] an offloading framework, named Ternary Decision Maker (TDM), has been developed, aiming to shorten response time and reduce energy consumption simultaneously with targets of execution including on-board CPU and GPU in addition to the cloud, from the point of view of the single device. In addition, there are many studies that focus on whether to offload computation to a server, providing solutions related to a yes/no decision for the entire task at one time [32], [33] or studies that focus on optimization of the energy consumption in SMDs necessary to run a given application under execution time constraint [34].
Differently from the literature, we propose a partial offloading technique able to exploit the HetNets scenario and the presence of MCC devices - the UMCC framework - by optimizing the amount of partial offloading of the computational tasks depending on the number of devices connected to a network and their location with respect to the WiFi access points or LTE eNodeBs. The SMDs can exploit the partial data offloading to distribute high computational tasks among centralized servers and local computing.
In Fig. 2.2 the workflow and the entities involved in the performance of a task are shown. From the point of view of a single user, the decision about offloading or not is taken on the basis of the following considerations:
- If the task is delegated to the cloud, the energy consumed by the mobile device is due to the data transfer - uploading data and downloading results - plus the energy consumed in an idle state during the outside computation - waiting for the results; the global time for having the task accomplished is related not only to the computational time but also to the transfer time for moving data from the mobile device to the cloud and vice-versa.
- If the task is computed locally, the energy consumed by the mobile device is due to the computation itself; the global time for having the task accomplished is related only to the computational ability of the SMD.

In this chapter the optimization of the entire system is considered, not for a single device but for the whole community of devices, by taking into account partial offloading in a non trivial multi-objective optimization approach, where both energy consumption and execution time constraints are considered. A cost function including the tradeoff between energy consumption of mobile devices versus the time to offloading data and to compute tasks on a remote cloud server is provided, evaluating the optimal offloading fraction depending on the network's load. It can be exploited when the network is overloaded and the tasks request large amounts both of computation to perform and data to exchange.
System Model
The reference scenario is characterized by a urban area with a pervasive wireless coverage, where several mobile devices are interacting with a traditional centralized cloud and request for services from a remote data center, as illustrated in Fig. 2.1. Alongside the presence of a pervasive wireless network, the system deals with many sensing and user terminals that generate and exploit a large amount of data. In order to connect the SMDs to the cloud and the data centers for delegating data for the computation, we take into account a simple categorization of the UMCC's trasmission entities, considering only two types of RATs forming the basic elements of the HetNets: macrocells and small cells. If, on one side, the strategy of delegating computation to the centralized cloud allows to exploit high performance computing centers, on the other side, it copes with the energy spent by the SMDs for transferring data. Similarly, the SMDs which compute locally the applications in a distributed approach, face with the energy issues due to the computation itself. In other words, the SMDs consumes energy both to delegate the application to the data centers and to compute it locally. Furthermore, both the speed to transmit data and the speed for local computation are related to the energy consumed by the SMDs. Thus, the offloading decision between offloading the application or computing it locally leads to a tradeoff. For this reason our model provides a cost function by resorting to a previously introduced model in [32], [33] which compares the energy used for a 100\% offloading with the ones used to perform the task locally. The parameters used in the following are listed in tab 2.1.
| symbol | meaning | unit of measure |
|---|---|---|
| $P_l$ | power for local computing | W |
| $P_\textit{id}$ | power while being idle | W |
| $P_\textit{tr}$ | power for sending and receiving data | W |
| $S_\textit{md}$ | SMD’s calculation speed | no. of instructions / s |
| $S_\textit{tr}$ | SMD’s transmission speed | bit / s |
| $S_\textit{cs}$ | cloud server’s calculation speed | no. of instructions / s |
| $C$ | instructions required by the task | no. of instructions |
| $D$ | exchanged data | bit |
In our scenario we suppose that the computation of a certain task requires $C$ instructions. $S_{\textit{md}}$ and $S_{\textit{cs}}$ are, respectively, the speeds in instructions per second of the mobile device and the cloud server. Hence, a certain task can be completed in an amount of time equal to $C/S_{\textit{md}}$ on the device and $C/S_{\textit{cs}}$ on the server. On the other hand, let us suppose that $D$ corresponds to the amount of bits of data that the device and the server must exchange for the remote computation, and $S_{\textit{tr}}$ is the transmission speed, in bit per second between the SMD and the access point; hence, the transmission of data lasts an amount of time equal to $D/S_{\textit{tr}}$. In this case we consider that the transmission time is mostly due to the access network transfer, because the transfer rate of the backbone network can be considered as negligible due to the higher data rate. Moreover, we consider as negligible the transfer time from the access point to the user terminal because the amount of data in response to the elaboration in centralized server is little with respect to the data sent to the centralized server [32], [33].
Hence, it is possible to derive the energy for local computing:
\begin{equation} \label{eq:E_locale} E_{l} = P_{l}\times\frac{C}{S_{\textit{md}}} \tag{2.1} \end{equation}as the product of the power consumption of the mobile device for computing locally, $P_{l}$, and the time $C/S_{\textit{md}}$ needed for the computation. Similarly, it is possible to derive the energy needed for performing the task computation on the cloud as the energy used while being in idle for the remote computation plus the energy used to transmit the whole data from the SMD to the cloud:
\begin{equation} \label{eq:E_OD100} E_{\textit{od}} = P_{\textit{id}}\times\frac{C}{S_{\textit{cs}}} + P_{\textit{tr}}\times\frac{D}{S_{\textit{tr}}}, \tag{2.2} \end{equation}where $P_{\textit{id}}$ and $P_{\textit{tr}}$ are the power consumptions of the mobile device, in watts, during idle and data transmission periods, respectively.
Similarly, it is possible to derive the time needed for the local computing as:
\begin{equation} \label{eq:T_locale} T_{l} = \frac{C}{S_{\textit{md}}} \tag{2.3} \end{equation}and the time for the whole offloading computing as
\begin{equation} \label{eq:T_OD100} T_{\textit{od}} = \frac{C}{S_{\textit{cs}}} + \frac{D}{S_{\textit{tr}}} \tag{2.4} \end{equation}In many applications, this approach is not efficient or feasible, and it is necessary to partition the application at a finer granularity into local and remote parts, which is a key step for offloading.
Adaptive Offloading
In this section, firstly, two equations are provided, to represent the energy used by a SMD to execute an application in partial offloading and to express the time needed to execute such application. Secondly, the impact of the traffic workload in the wireless network is taken into account, since the RATs and the number of SMDs entails the transmission speed of the the offloading data. Thirdly, a cost function is introduced, to evaluate the percentage of offloading which minimizes both energy and time.
In order to analyze the energy spent for offloading only a part of the application, we introduce the weight coefficients ${\gamma}$ and ${\delta}$, satisfying ${0 \le \gamma ,\delta \le 1}$, representing respectively the percentage of the computational task and the percentage of the exchanged data for offloading. Then, the used energy of a single device ${E_{\textit{part}\_\textit{od}}}$ has been introduced, as the sum of the one spent to perform a part of the task locally plus the one spent to idle and transmit the other part of the task to the cloud:
\begin{equation} E_{\textit{part}\_\textit{od}} = P_{l}\times\frac{(1-\gamma)\cdot C}{S_{\textit{md}}} + P_{\textit{id}}\times\frac{\gamma\cdot C}{S_{\textit{cs}}} + P_{\textit{tr}}\times\frac{\delta\cdot D}{S_{\textit{tr}}} \label{eq:E_ODpart} \tag{2.5} \end{equation}Taking into account the same coefficients $\gamma$ and $\delta$ used in eq. \ref{eq:E_ODpart}, we can calculate the time for the partial offloading ${T_{\textit{part}\_\textit{od}}}$ as the maximum between the time needed for computing the local part of the task and the time needed for the offloading, considering the two phases performed in the same time:
\begin{equation} \label{eq:T_ODpart} T_{\textit{part}\_\textit{od}} = \max \left(\frac{(1-\gamma)\cdot C}{S_{\textit{md}}};\quad\frac{\gamma\cdot C}{S_{\textit{cs}}} + \frac{\delta\cdot D}{S_{\textit{tr}}}\right) \tag{2.6} \end{equation}The structure and the workload of the network are implicitly considered in eqs. \ref{eq:E_ODpart} and \ref{eq:T_ODpart}. Now we are going to describe the effect on ${E_{\textit{part}\_\textit{od}}}$ and ${T_{\textit{part}\_\textit{od}}}$ due to the different RATs performing in the HetNets and to the amount of devices connected to this different RATs. The HetNet mainly consists of two components, macrocells and small cells, with different bandwidths ${\textit{BW}}$. Since, for a single SMD, the speed rate of the data exchange ${S_{\textit{tr}}}$ is affected by the bandwidth of the node to which the SMD is connected, by the distance ${d}$ from this node, and by the number ${n}$ of the overall SMDs connected to the same node, ${S_{tr}}$ can be written in an explicit way as:
\begin{equation} \label{eq:Str} S_{tr} = \frac{\textit{BW}}{n}\cdot \log_2{\left(1+\frac{\textit{SNR}}{d^2}\right)} \tag{2.7} \end{equation}where $\textit{SNR}$ is the SNR, typical parameter of the device.
In order to allow the evaluation of the offloading percentage, aiming to save energy and improve performance, the introduction of a cost function that can consider the minimization of both eqs. \ref{eq:E_ODpart} and \ref{eq:T_ODpart} for the entire set of SMDs is required. This is a non-trivial multi-objective optimization problem that we addressed by setting the cost function as a weighted sum of both the average values, with $\alpha$ and $\beta$ coefficients with the constraints $0\le\alpha,\beta\le1$ and $\alpha+\beta=1$, $N$ number of network's devices and ${E_l}$, ${T_l}$ reference values representing average energy and time spent when the task is computed locally by a SMD:
\begin{equation} \label{eq:FCost} F = \alpha \frac{\frac{1}{N}\sum_{k=1}^N E_{\textit{part}\_\textit{od},k}(\gamma,\delta)}{E_l} + \beta \frac{\frac{1}{N}\sum_{k=1}^N T_{\textit{part}\_\textit{od},k}(\gamma,\delta)}{T_l} \tag{2.8} \end{equation}This cost function is based on a network centric approach in which a central entity is responsible for choosing values of the offloading percentage $\gamma$ and $\delta$ after collecting informations about the SMDs' features. Furthermore, in the partial offloading procedure, $\gamma$ and $\delta$ are bounds, because before a task is executed it may require certain amount of data from other tasks [23]. Moreover, the weighted coefficients $\alpha$ and $\beta$ are chosen at a main level to give a major importance to energy or time saving.
Numerical Results
During a partial offloading the amount of energy and time in eqs. \ref{eq:E_ODpart} and \ref{eq:T_ODpart} is affected by the percentage of computation and communication exchanged, represented respectively by the coefficients $\gamma$ and $\delta$. These are correlated each other, since the execution of a remote computation task requires a certain amount of input/output data to be exchanged. So we can consider the ratio $\delta/\gamma$ as a typical value, peculiar of a type of application. To summarize typical scenarios we have taken into account three kinds of applications represented in Table 2.2, according to the aims to analyze cases of a smart transportation system [35]
| Application | Computation | Data Transmission | C | D | $\delta/\gamma$ |
|---|---|---|---|---|---|
| 1 - Real time traffic analysis | High | Low | $10^7$ | $10^5$ | $0.25$ |
| 2 - Mobile video and audio communication | Low | High | $10^5$ | $10^7$ | $0.75$ |
| 3 - Mobile Social Networking | High | High | $10^7$ | $10^7$ | $0.50$ |
We considered a deployment area of $1000\times1000\ m^2$, where one LTE eNodeB with channel capacity equal to 100 MHz and three WiFi access point with channel capacities equal to 22 MHz are positioned to cover the entire area. Specifically, the access points are positioned at point (0,0), (500,1000) and (0,1000), and the LTE station at (500,500), as shown in fig. 2.3.
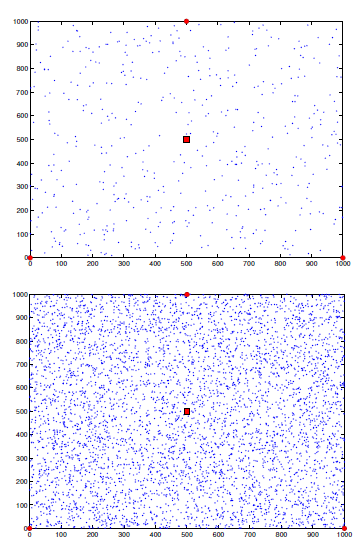
The values of $S_{\textit{md}}$, $P_{\textit{id}}$, $P_{\textit{tr}}$ and $P_l$ are specific parameters of the mobile device. For example we utilized the values of an HP iPAQ PDA with a 400 MHz Intel XScale processor ($S_{\textit{md}}=400$) and the following values: $P_l\approx0.9 W$, $P_{\textit{id}}\approx0.3 W$ and $P_{\textit{tr}}\approx1.3 W$ [32].
The cost function coefficients, $\alpha$ and $\beta$, are equal to 0.5, aiming to give the same importance to both time and energy consumptions. In Figures 2.4, 2.5, and 2.6 the performance results of the cost function are represented for the three applications described in tab 2.2.
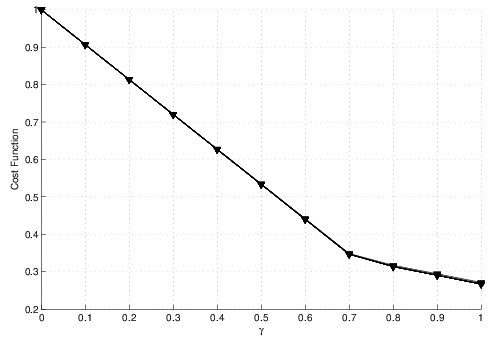
Fig. 2.4 shows that, when a task requires high computation and low communication, i.e. Application 1, it is better to offload the task totally, no matter how many devices are connected to the network. In fact, the curves are overlapped and the cost function assumes the sames values for the same percentage $\gamma$.
On the other hands, Fig. 2.5 shows that, when a task requires low computation and high communication, i.e. Application 2, it is better to compute the task locally. In this case a big number of connected devices affects the cost function in a negative way; it is possible to see that there is a minimum for $\gamma$ = 0.
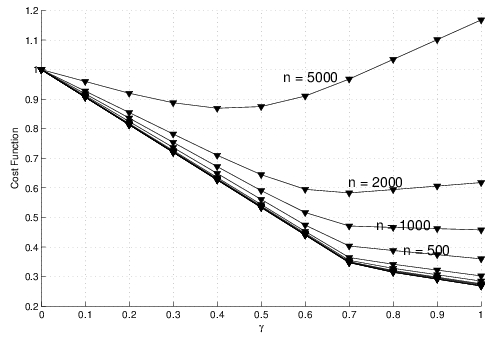
The most interesting case is shown in Fig. 2.6. In fact, when the network is overloaded, tasks with both a large amount of computation to execute and data to exchange - as in Application 3 - are better performed for a specific value of $\gamma$. For example, in this case, the best performance is for $\gamma = 0.4$ when a population of 5000 devices is whithin the area, and $\gamma= 0.7$ for a population of 2000 devices. When the network is not overloaded, instead, as in cases of less devices within the area, it's better to perform the total offloading.

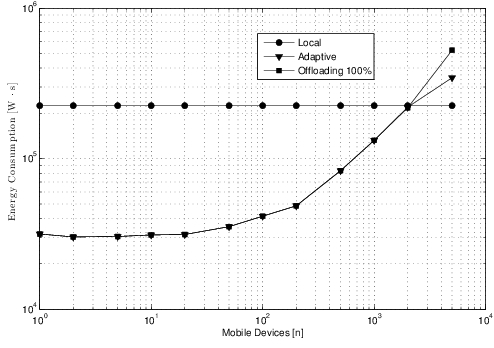
Finally, as shown in \autoref{fig:enApp3adapt} and \autoref{fig:timeApp3adapt}, we compare energy and time spent in the adaptive case with those spent for the local execution and the total offloading case to perform Application 3; for the adaptive algorithm we have considered the use of the optimized $\gamma$ parameter following the previous analysis. While for the energy there is a compromise between the two boundary cases, the adaptive function allows the best performance considering time as the primary issue.
Conclusions
In this chapter, a cost function has been defined for optimizing contemporaneously time and energy consumption in a scenario where smart mobile devices are supposed to perform an application; the aim was to optimize the amount of computation performed locally and remotely. The remote execution is faster and can relieve mobile devices from the correlated energy consumption, but it involves data exchange with the cloud server, spending time and energy to transmit, depending also from the load of the HetNet. The cost function is proposed to evaluate the percentage of application to offload for time and energy optimization. The results show that for applications requesting both high execution work and data exchange a particular value of this percentage, depending on the number of devices, optimize the performance.
A User-Satisfaction Based Offloading Technique for Smart City Applications
Introduction
New user's needs cause a major boost of wireless communication techniques employed in smart cities, as well as a rapid growth and diffusion of enhancing technologies. To achieve the goal of interacting with city services, allowing to simplify everyday life, MCC and HetNets become together the killer applications for resolving the significant facing problems: the former for offloading application to powerful remote servers, shortening execution time and extending battery life of mobile devices, the latter for exploiting high-speed and stable connectivity in an ever grown mobile traffic trend, allowing the use of small cells in addition to macrocells [23]. In such a scenario users can access to remote resources without interruption in time and space.
In this context, energy saving and performance improvement of SMDs have been widely recognized as primary issues. In fact, the execution of every complex application is a big challenge due to the limited battery power and computation capacity of the mobile devices [25]. The distributed execution between the cloud and mobile devices has been widely investigated [9], highlighting the challenges towards a more efficient cloud-based offloading framework and also suggesting some opportunities that may be exploited. Indeed, the joint optimization of HetNets and distributed processing is a promising research trend [5]. We envision that the success of HetNets, jointly with MCC, would ultimately depends on user satisfaction, which in turn relies on saving energy and computing application quickly. Identifying the relevant QoS for each of the diverse application types and distinguishing the variation of user satisfaction related to the QoS is a research challenge [36].
Various mobile data offloading policies are proposed in the literature where the partial offloading of data to the network infrastructure is performed according to the variations of the network conditions and the operator strategies [37]; however, a model related to user satisfaction regarding battery saving and speed of computation is not already taken in consideration.
In this chapter we propose a utility function model that takes into account a series of parameters related to HetNet's nodes, SMDs' characteristics and types of performed application. We categorize applications in different classes, and consider for each application type the amount of data and computation transferred to the MCC and how the HetNet traffic load affects the power consumption of the SMDs and their execution time. The opportunity to move to the cloud a portion of the computing application is taken into account, because the decision whether moving the computation tasks of mobile applications from the local SMDs to the remote cloud involves a tradeoff between energy consumption and computational time [38].
The proposed utility function takes into account the QoS parameters in terms of throughput, amount of energy used by the SMDs and time spent to execute the application. Furthermore, it acts as input for a CA procedure aiming to select the best access point for respecting the system requirements. The user-satisfaction CA algorithm is compared with a legacy algorithm that foresees the connection with the nearest access point. The results show that when the network is overloaded, the algorithm based on the proposed utility function offers a better service with respect to the nearest-node technique, since the average throughput is stable, allowing less outage of connectivity and reduced values of average energy and average time in comparison to the nearest-node algorithm.System Model
The system model we are focusing on relies on the results of the chapter 2.. We consider a reference scenario analogous to fig. 2.1, but, in this case, various SMDs are requesting three different types of application, with a casual uniform distribution. Each type is partially offloaded giving the optimization problem investigated previously. The SMDs are interacting with a traditional centralized cloud requesting for offloading through two types of RAT that compose the basic elements of the HetNet: macrocells and small cells.
Recalling the characteristics the system is premised on, we can summarize:
- a certain application requires $O$ operations and $D$ data,
- the speeds of the mobile device and of the cloud server are, respectively, $S_{\textit{md}}$ and $S_{\textit{cs}}$
- the speed of the mobile device for transferring data to the access point is $S_{\textit{tr}}$
- the weight coefficients representing, respectively, the fraction of the computational task and the fraction of the data sent for the offloading are ${\gamma}$ and ${\delta}$, satisfying ${0 \le \gamma ,\delta \le 1}$
We recall also that the transmission time is mostly due to the access network transfer, by considering as negligible the transfer time on the backbone network between the access point and the cloud server, due to the higher data rate, and the return time from the cloud server to the user terminal because the amount of data in response to the elaboration in the cloud server is small with respect to the data sent toward the cloud server [32], [33].
The values $\gamma$ and $\delta$, previously found in the optimization procedure of chapter 2, have been considered here for each selected application. We will focus on three application types, characterized by a specific amount of required operations $O_k$, amount of data that need to be exchanged $D_k$, fraction of offloaded computational tasks $\gamma_k$, and fraction of offloaded data $\delta_k$, as defined in Table 3.1. The considered application classes are:
- Real time road traffic analysis: the applications aiming to optimize the route toward a certain destination (e.g., navigation applications);
- Mobile Video and Audio Communications: the applications that elaborates user generated audio and video content;
- Mobile Social Networking: the applications used for social networking.
| Application | $O_k$ | $\gamma_k$ | $D_k$ | $\delta_k$ |
|---|---|---|---|---|
| 1 - Real time traffic analysis | $10^7$ | $0.9$ | $10^5$ | $0.25$ |
| 2 - Mobile video and audio communication | $10^5$ | $0.1$ | $10^7$ | $0.07$ |
| 3 - Mobile Social Networking | $10^7$ | $0.7$ | $10^7$ | $0.35$ |
In order to describe the throughput, the consumed energy and the time spent by a device for the computation - the three measures we chose for the QoS evaluation - let us focus now on the network infrastructure, by considering a generic couple composed by the $i$-th access point and the $j$-th SMD.
Throughput ${S_{\textit{tr},\textit{ij}}}$ The throughput ${S_{\textit{tr},\textit{ij}}}$ is affected by the bandwidth ${\textit{BW}}_{i}$ of the $i$-th access point, by the distance ${d_{\textit{ij}}}$ between the access point and the SMD, by the signal to noise ratio $\textit{SNR}_i$ at the receiver, and by the number of devices $n_i$ already connected to the $i$-th access point. By resorting to the Shannon formula, the throughput ${S_{\textit{tr},\textit{ij}}}$ can be written as:
\begin{equation} \label{eq:Str2} S_{\textit{tr},\textit{ij}} = \frac{{\textit{BW}}_{i}}{n_i}\cdot \log_2 {\left(1+ \frac{\textit{SNR}_{i}}{d_{\textit{ij}}^2}\right)} \tag{3.1} \end{equation}Energy $E_{\textit{part}\_\textit{od},\textit{ijk}}$The energy spent for the partial offloading can be written as the sum of the energy spent to perform locally a part of the task and the energy spent during the idle period and during the transmission of the remaining part of the task to the cloud; the idle period corresponds to the amount of time needed by the cloud to perform the computation: we suppose that during this time the SMD remains in an idle state. In this case it is possible to derive the overall spent energy for the $k$-th application as:
\begin{equation} E_{\textit{part}\_\textit{od},\textit{ijk}} = P_{\textit{l,j}}\times\frac{(1-\gamma_{k})\cdot O_{k}}{S_{\textit{md,j}}} + P_{\textit{id,j}}\times\frac{\gamma_{k}\cdot O_{k}}{S_{\textit{cs}}} + P_{\textit{tr,ij}}\times\frac{\delta_{k}\cdot D_{k}}{S_{\textit{tr,ij}}} \tag{3.2} \label{E_ODpart} \end{equation}where $P_{l,j}$ corresponds to the power consumption for performing the local computation by the $j$-th SMD, $P_{\textit{id,j}}$ is the power consumption of the $j$-th SMD in idle state, $P_{\textit{tr,ij}}$ is the power consumption of the $j$-th SMD for transmitting the data to the $i$-th access point, and $S_{\textit{md,j}}$ is the computing speed in operations per second of the $j$-th SMD.
Time $T_{\textit{part}\_\textit{od},\textit{ijk}}$The computation time for executing the application can be written as the maximum value between the time needed to compute the local portion of the task and the time needed for the offloaded portion; we have supposed that the two phases can be performed at the same time, so that the overall time corresponds to the maximum value:
\begin{equation} \label{T_ODpart} T_{\textit{part}\_\textit{od,ijk}} = \max \left(\frac{(1-\gamma_{k})\cdot O_{k}}{S_{\textit{md,j}}};\quad\frac{\gamma_{k}\cdot O_{k}}{S_{\textit{cs}}} + \frac{\delta_{k}\cdot D_{k}}{S_{\textit{tr,ij}}}\right) \tag{3.3} \end{equation}User-Satisfaction Based Utility Function
We introduce, for each of the three quality parameters taken in consideration, a function representing the QoS degree perceived by the user. The functions are modeled as sigmoid curves, since they are well-known functions often used to describe QoS perception [24], [36], [39]. A sigmoid curve can be defined as:
\begin{equation} U(x)=\frac{1}{1+e^{-\alpha (x-\beta)}} \tag{3.4} \label{eq:sigmoid} \end{equation} where $\alpha$ and $\beta$ decide the steepness and the center of the curve. The value of $\alpha$ indicates user's sensitivity to the QoS degradation, while $\beta$ indicates the acceptable region of operation. The derivative of the sigmoid function describes the subject perception, so that it does not make sense to give more resources over a certain value above which the derivative of the utility function approximates to zero.Focusing on the three QoS parameters we are considering, i.e., throughput, energy and time, it is possible to define the related sigmoid functions, by taking into account that the user satisfaction grows with higher throughput values and lower energy and time values. To this aim, concerning the user throughput, it is possible to define the related sigmoid function as:
\begin{equation} \label{eq:s} f_1(S_{\textit{tr},\textit{ij}}) = \frac{1}{1+e^{-\alpha_1 (S_{\textit{tr},\textit{ij}}-S_{\textit{tro,k}})}} \tag{3.5} \end{equation}where $S_{\textit{tro,k}}$ is the objective throughput value for the $k$-th application.
On the other hand, since the energy and time parameters need to decrease for increasing the user satisfaction, the related cost functions need to be decreasing sigmoid functions defined as:
\begin{equation} \label{eq:e} f_2(E_{\textit{part}\_\textit{od},\textit{ijk}}) = 1 - \frac{1}{1+e^{-\alpha_2 (E_{\textit{part}\_\textit{od},\textit{ijk}}-E_\textit{o,k})}} \tag{3.6} \end{equation} \begin{equation} \label{t} f_3(T_{\textit{part}\_\textit{od},\textit{ijk}}) = 1 - \frac{1}{1+e^{-\alpha_3 (T_{\textit{part}\_\textit{od},\textit{ijk}}-T_\textit{o,k})}} \tag{3.7} \end{equation}The parameter $\alpha_q$ ($q = 1,2,3$) is defined as the steepness of $f_q$ and is related to the user's sensitivity to the QoS degradation of the $q$-th parameter. The parameters $S_\textit{tro,k}$, $E_\textit{o,k}$ and $T_\textit{o,k}$ are the center points of the curves $f_q$, indicating the acceptable region of operation. $S_\textit{tro,k}$ and $T_\textit{o,k}$ are reference values for the data transmission rate and the computing time related to the type of application requested, whereas $E_\textit{o,k}$, the energy spent to compute le application locally, is also associated to the type of device in addition to the type of application. For the goal of this study, referring to network analysis rather than SMD's types analysis, we considered values of $E_\textit{o,k}$ dependent only to application types. The values of $S_\textit{tro,k}$, $E_\textit{o,k}$ and $T_\textit{o,k}$ in relation with the application classes are defined in tab. 3.2.
| Application | $S_\textit{tro,k}$ | $E_\textit{o,k}$ | $T_\textit{o,k}$ |
|---|---|---|---|
| 1 - Real time traffic analysis | $0.52$ | $2.9 | $0.5$ |
| 2 - Mobile video and audio communication | $1.42$ | $3.6$ | $0.1$ |
| 3 - Mobile Social Networking | $0.93$ | $7.1$ | $2$ |
On the basis of the QoS sigmoid functions, we introduce a model developed from the economic concept of utility function [39]. By focusing on the access point $i$ (related to the type of RAT) and the SMD $j$, the cost function for the association of the $j$-th SMD to the $i$-th access point is given by:
\begin{equation} \label{eq:Utilityfunction} \textit{U}_{\textit{ij}} = c_1\cdot f_1(S_{\textit{tr},\textit{ij}}) + c_2\cdot f_2(E_{\textit{part}\_\textit{od},\textit{ijk}}) + c_3\cdot f_3(T_{\textit{part}\_\textit{od},\textit{ijk}}) \tag{3.8} \end{equation}where $S_{\textit{tr},\textit{ij}}$, $E_{\textit{part}\_\textit{od},\textit{ijk}}$ and $T_{\textit{part}\_\textit{od},\textit{ijk}}$ are the QoS parameters related to the connection between the $i$-th access point and the $j$-th SMD for partial offloading of the $k$-th application. The weight parameters $c_q$ are associated to the importance of the respective quality-related parameters in the performance of the application. For example, for an application of type 1 (real time road traffic analysis) a high weight $c_1$ (related to $S_\textit{tr}$) is required, rather then in an application of type 2 (Mobile Video and Audio Communication) where it is more important to have a low delay time, therefore a high value of $c_{3}$.
The weight parameters $c_q$ are normalized with respect to a certain application, so that it is possible to assume that: $$\sum_{h=1}^3 c_h=1. \tag{3.9}$$ for each application $k$. Table 3.3 shows the considered weight parameters for each type of application; it is worth to be noticed that, higher is a certain parameter $c_k$ for a certain application $k$, higher is the importance of the related QoS parameter for the selected application.
| Application | $c_1$ | $c_2$ | $c_3$ |
|---|---|---|---|
| 1 - Real time traffic analysis | $0.6$ | $0.2$ | $0.2$ |
| 2 - Mobile video and audio communication | $0.2$ | $0.2$ | $0.6$ |
| 3 - Mobile Social Networking | $0.2$ | $0.2$ | $0.6$ |
Cell Association
The above defined utility function is at the basis of the CA scheme that allows the selection of the best access point by the SMD, for respecting the requirements of the considered applications; whenever a SMD requests to offload an application, the utility function is evaluated for each access point of the network. The SMD will connect to the access point with the maximum utility function.
The selection of a certain access point for establishing the connection could modify the values $S_\textit{tr}$, $E_{\textit{part}\_\textit{od}}$ and $T_{\textit{part}\_\textit{od}}$ for the SMDs already connected with the same access point. Hence, the utility function related to those SMDs is evaluated again, by considering the new incoming SMD. The cell association algorithm is reported in Algorithm 1, where it is possible to note the utility function elaboration and the updating of the utility function for all the SMDs already connected to the selected access point.The CA algorithm is performed for all the SMDs in the scenario.

Numerical Results
This section deals with the numerical results of the proposed utility function approach by resorting to computer simulations. The smart city scenario has been modeled in Matlab by considering a randomly placed number of SMDs in a deployment area of $1000\times1000\ m^2$, where one LTE eNodeB with channel capacity equal to 100 MHz and three WiFi access points with channel capacities equal to 22 MHz are positioned to cover the entire area. The SMDs, positioned randomly, will connect to one of the access point/eNodeB, depending on the cell association policy; to this aim we suppose that all the SMDs are capable to connect to both WiFi and LTE. The infrastructures are positioned in the same configuration as represented in Fig. 2.3, where the access points are positioned at point (0,0), (500,1000) and (0,1000), and the LTE eNodeB at (500,500).
The SMDs, positioned randomly, request in sequence to offload a random application type and are connected accordingly, on the basis of the presented cell association algorithm. The values $S_{\textit{md}}$, $P_{\textit{id}}$, $P_{\textit{tr}}$ and $P_l$ are specific parameters of the mobile devices. We utilized the values of an HP iPAQ PDA with a 400 MHz Intel XScale processor ($S_{\textit{md}}=400$) and the following values: $P_l\approx0.9 W$, $P_{\textit{id}}\approx0.3 W$ and $P_{\textit{tr}}\approx1.3 W$. As for the cloud server used for the offloading we suppose that $S_{cs}$ = 8000 [32].
In the same way used for the utility function, we have resorted to the following values for the steepness of the sigmoidal functions: $\alpha_1 = 1.6\cdot 10^{-3}$, $\alpha_2 = 10^{-6}$, and $\alpha_3 = 10^{-6}$. These values have been selected after a numerical optimization phase as reported in chapter 2. We have supposed that the three applications are equally distributed among all the SMDs existing in the environment, so that they have same probability equal to 1/3.
The numerical results are reported by focusing on the performance in terms of average energy consumption, computational time and throughput for each SMD. The numerical results have been compared with three other approaches: local computation, total offloading and nearest node. For the local computation algorithm is assumed that the computation is performed locally by each SMD; in this case no data is exchanged on the network. In the total offloading algorithm an opposite situation is assumed, since nothing is computed locally, while the entire data load is offloaded to the centralized cloud servers. The nearest node algorithm, finally, assumes that each SMD will connect to the nearest AP/eNodeB.
In fig. 3.1 the results in terms of energy consumption are reported. It is possible to note that both the utility function and the nearest node approaches outperform the local computing and the total offloading. Moreover, it is possible to note that the utility function algorithm allows to have almost the same values for different numbers of nodes, outperforming the nearest node approach for increasing number of SMDs. A similar behavior can be noted in terms of average time for executing the application, in fig. 3.2, where, also in this case, the utility function algorithm outperforms the other approaches.
In fig. 3.3, the performance in terms of average throughput has been reported. In this case the performance for the local computation approach is not reported because in this case no data transfer occurs. It is possible to note that the throughput for the utility function algorithm remains stable, hence giving an optimized value to each SMD, while in the nearest node approach the throughput decreases when the number of SMDS increases.



Conclusions
In this chapter we introduced a utility function derived from the economic world aiming to optimize the cell association of the smart devices for achieving low energy consumption and computational time while maximizing the overall throughput. The proposed approach allows to increase the performance with respect to a nearest node association, and with respect to statical approaches where the computation is performed locally or is completely offloaded.
A Cluster Based Computation Offloading Technique for the UMCC
Introduction
The evolutionary trends of the Information Society have lead to the definition of the smart city as the most challenging scenario for the IoT applicability. Among several things composing a smart city, the computing infrastructures are responsible for giving a distributed elaboration intelligence to the environment aiming at providing unprecedented services and efficiency. The increasing number of devices, appliances, smartphones and objects connected to the Internet has lead to the introduction of the IoT paradigm, aiming at design the network infrastructure as composed by a multitude of devices collaborating each others. Among several different functions provided by the IoT devices, the distributed computing approach seems to have an increasing interest allowing to establish an interaction between the IoT and the MCC worlds [7], [40].
This chapter takes into consideration the computation offloading towards other SMDs pooled together, in addition to powerful remote servers, with the aim of an exploitation for shortening execution time and extending battery life. The actual innovation is to take into account different types of mobile cloud infrastructures, considering also a non-trivial extension of the MCC paradigm to the edge of the network, where a collaborative crowd of end-user clients or near-user edge devices share storage, communication, computation, and control. In this context, the issues of mobile device energy saving and performance improvement become increasingly a source of concern, because of the strict constraints on their memory capacity, network bandwidth, CPU speed and battery power [25]. The proposed cluster based computation offloading technique is able to work in a distributed environment, in order to better satisfy the QoS requirements of the SMD users, by minimizing a cost function that takes into account the already mentioned tradeoff between SMD's energy consumption and execution time. By analyzing an actual case of this very complex system, we introduce an algorithm for offloading a real-time navigation application in a distributed fashion, aiming to minimize the execution time.
Although the computation offloading can significantly increase the data processing capabilities for each mobile user, it is challenging to achieve an efficient coordination among the entire set of requesting devices, because this operation can affect the efficiency of the CCIs, since the channel capacity has to be shared among all the devices, causing a reduction of the throughput experienced by each user. This could make not convenient the offloading operation [41].
Several excellent works have been done to study cloud and radio resource management issues; among them in the last years there is an increasing importance in the collaborative mobile device offloading [42], [43], [44], as well as other considerable studies that face up jointly to clouds and fog architectures [13], [45]. Further, this investigation proposes a system model that takes into account jointly a series of features related to HetNet nodes, different CCIs - in particular a distributed cloud of devices merged together to share resources - and various SMDs’ characteristics [46], [47].
In this chapter we consider a system where users can interact with all the different topologies of cloud - centralized, cloudlets, and distributed mobile cloud - as described in section 1.2. This allows users to optimize the system performance by offloading a fraction of the application among different cloud structures. The advantage of this approach consists in computing the application that is referred to a specific service exploiting the different cloud infrastructures and network technologies, optimizing important characteristics of the system, i.e. maximize throughput and time computation or minimize the energy used by the SMDs.
A cost function is introduced to optimize the nodes assignment and the resources allocation for distributing the application through the system. In particular we focused on a cluster based solution aiming at exploiting the MCC environment for executing an application in a distributed fashion, for handling a real-time navigation application in a vehicular environment.
Application Scenario
We consider a UMCC environment where each SMD aims at performing an application, interacting with many CCIs through different wireless connections, in order to distribute the computation load to one or more CCIs and receive data results from the CCIs themselves. We will consider the possibility of distributing the computation load exploiting multiple CCIs at the same time, for offloading to each one of them a different part of the application. In this chapter we neglect the storage optimization, since each device is supposed to own a storage capacity fitting its computation load. This simplification allows to focus on the proper computation offloading optimization.
A SMD can delegate computation functions towards one or more CCIs for performing the requested application. The CCIs can be distinguished on the basis of their features and are classified following the three types described in section 1.2: an ubiquitous centralized cloud infrastructure, many roadside cloudlet infrastructures, and a distributed cloud infrastructure composed by neighboring SMDs pooled together for resource sharing. The centralized cloud refers to an infrastructure with a huge amount of storage space and computing power, virtually infinite, offering the major advantage of the elasticity of resource provisioning. The cloudlets are instead fixed small cloud infrastructures available in a delimited area, installed in proximity of the users and provided with a dedicated transmission node that supports the wireless communication into this area. Finally, the distributed cloud is a a Mobile Ad-hoc Network (MANET) composed by the neighboring SMDs.
From the computational point of view, the centralized cloud allows to reduce the computing time by exploiting powerful processing units, but it could suffer from the distribution latency, due to the remote data transfer. Cloudlets, instead, allow to decrease the distribution latency with respect to the centralized cloud, but the storage capacity and the computation power are reduced. Finally, a distributed cloud is composed by the SMDs themselves sharing their own amount of resources depending on the instantaneous usage.
The communication side consists of all the wireless connections available within the selected smart city environment allowing to exploit the centralized cloud, various cloudlet nodes and the SMDs themselves. Aim of the selected system is to divide a certain smart city application into different parts and distribute them among the available nodes. In case a fraction of an application is distributed towards the centralized cloud infrastructure, one of the available HetNet nodes is used for the offloading operation. In case of computation offloading towards a roadside cloudlet infrastructure, the only available node is the one provided in the proximity of the cloudlet itself. In case of computation offloading towards other SMDs belonging to the distributed cloud infrastructure, the transferring operation is made directly by the SMD. Besides, part of the application can be computed locally by the SMD requesting the application. Referring to figure 1.3, we consider the complete distribution, exploiting each of the CCIs represented.
The Partial Distributed Offloading Model
Even if every SMD of the system can simultaneously requests the computation offloading of one or more applications, we are focusing on a scenario where a single requesting smart mobile device wants to perform an application $App$, whereas all the other SMDs are considered only for receiving and computing it. This simplification does not prevent the generalization of the system, as we can consider the general case as an extension composed by the overlapping of many simplified cases.
The application $App$ is defined through the number of operations to be executed, $O$, and the amount of data to be exchanged, $D$. The $App$ is running on a certain SMD, named Requesting Smart Mobile Device RSMD, that is the SMD requesting to the CCIs to execute the $App$. We focus for the moment on the presence of a single $App$ and a single requesting RSMD.
We suppose that the system demands some features in terms of QoS, in order to have a reliable execution of the $App$. We have taken into account:
- latency: the interval between a task of the application is requested and its results are acquired,
- energy consumption: the amount of energy the RSMD consumes for performing the application.
Thus, being $T_{\textit{RSMD}}$ and $E_{\textit{RSMD}}$, respectively, the amount of time and energy spent by the RSMD for offloading the application, the system optimization consists in minimizing a weighted sum of the normalized $T_\textit{RSMD}$ and $E_\textit{RSMD}$, giving more weight to the first or the second parameter depending on the importance of minimizing the energy consumption or the latency:
\begin{equation} \label{eq:latency-energy} w_E \frac{E_\textit{RSMD}}{E_o} + w_T \frac{T_\textit{RSMD}}{T_o} \tag{4.1} \end{equation}where $w_E$ and $w_T$ are the weight coefficients, and $E_o$ and $T_o$ reference values.
Both $T_\textit{RSMD}$ and $E_\textit{RSMD}$ depend on the parameters $O$ and $D$ of the $App$ and on the overall throughput $\eta_\textit{RSMD}$ between the nodes and the RSMD, hence, we can rewrite the eq. \eqref{eq:latency-energy}, for emphasizing this dependency, as:
\begin{equation} \label{eq:latency-energy2} w_E \frac{E_\textit{RSMD}(O,D,\eta_\textit{RSMD})}{E_o} + w_T \frac{T_\textit{RSMD}(O,D,\eta_\textit{RSMD})}{T_o} \tag{4.2} \end{equation}The system is composed by $M$ available HetNet nodes for offloading towards the centralized cloud (marked as $\textit{HN}$), $N$ cloudlets nodes (marked as $\textit{CL}$), and $K$ SMDs' nodes (marked as $\textit{MD}$), for sharing the computation in the distributed cloud. Thus, being $\eta_\textit{Xi}$ the throughput offered by the $i^{th}$ node of type $X$, where $X$ stands for $\textit{HN}$, $\textit{CL}$, and $\textit{MD}$, it results that $\eta_\textit{RSMD}$ is the sum of the throughput offered by the nodes available for the transfer operation:
\begin{equation} \label{eq:throughput4} \eta_\textit{RSMD} = \sum_{i=1}^\textit{M} \eta_\textit{HNi} + \sum_{i=1}^\textit{N} \eta_\textit{CLi} + \sum_{i=1}^\textit{K} \eta_\textit{MDi} \tag{4.3} \end{equation}where we suppose that the RSMD can connect ideally with all the available nodes. The throughput $\eta_\textit{Xi}$ is related to the number of SMDs $n_\textit{Xi}$ connected to the $i^{th}$ node and the channel capacity $BW_\textit{Xi}$ of the $i^{th}$ node, and can be expressed by resorting to the Shannon Formula:
\begin{equation} \eta_\textit{Xi} = \frac{\textit{BW}_\textit{Xi}}{n_\textit{Xi}}\cdot \log_2{\left(1+\frac{\textit{SNR}}{{d_\textit{Xi}}^2}\right)} \tag{4.4} \label{eq:shannon4} \end{equation}where $\textit{SNR}$ is a reference signal to noise ratio value of the RSMD at a distance equal to 1m and $d_\textit{Xi}$ is the distance between the RSMD and the $i^{th}$ node. We have considered for simplicity a no fading-affected channel; this simplification does not affect the operating principles of the framework. Furthermore, we assume a uniform distribution of the available bandwidth among all the $n_\textit{Xi}$ nodes.
$T_\textit{RSMD}$ can be defined as the sum of the time spent to perform locally part of the task, $T_\textit{l}$, plus the time spent to transmit data to the clouds, $T_\textit{tr}$, plus the time spent during the idle period, $T_\textit{id}$, waiting for the computation performed outside and the results transmitted back. In this case we assume that the transmission time is mostly due to the access network, because the backbone network data rate is much higher. Hence, we can write:
\begin{equation} \label{eq:latencyRSMD} T_\textit{RSMD} = T_\textit{l} + T_\textit{tr} + T_\textit{id} \tag{4.5} \end{equation}$T_\textit{l}$ can be evaluated as the ratio between the fraction of operation computed locally, $\alpha_0 O$ (where $\alpha_0$ is the percentage of operations $O$ computed locally), and the computing speed of the RSMD, $f_\textit{l}$:
\begin{equation} \label{eq:Tl} T_\textit{l}= O \frac{\alpha_0}{f_l} \tag{4.6} \end{equation}$T_\textit{tr}$ is the sum of the transferring times towards each node, corresponding to the ratio between the amount of transferred data $\beta_\textit{Xi} D$ (where $\beta_\textit{Xi}$ is the percentage of transferred data $D$ to the $i^{th}$ node), and the throughput of the node, $\eta_\textit{Xi}$. Thus we can write:
\begin{equation} \label{eq:Ttr} T_\textit{tr} = D \left ( \sum_{i=1}^\textit{M}\frac{\beta_\textit{HNi}}{\eta_\textit{HNi}} + \sum_{i=1}^\textit{N}\frac{\beta_\textit{CLi}}{\eta_\textit{CLi}}+ \sum_{i=1}^\textit{K}\frac{\beta_\textit{MDi}}{\eta_\textit{MDi}} \right ) \tag{4.7} \end{equation}$T_\textit{id}$ depends on the starting time and the duration of the offloaded computations. Since each CCI is able to compute it own task independently and simultaneously with the other CCIs, and since an offloaded computation cannot begin until all the data needed for performing it are provided, $T_\textit{id}$ would be optimized.
We consider for simplicity the worst case for $T_\textit{id}$, i.e., the maximum value among every duration of the offloaded computations. Furthermore, by defining as $f_\textit{CLi}$ and $f_\textit{MDi}$ the computing speed of the $i^{th}$ cloudlet and the $i^{th}$ SMD, respectively, and $f_\textit{CC}$ the computing speed of the centralized cloud, and considering $\alpha_\textit{Xi}$ the precentage of computed operations $O$ within the $i^{th}$ node, $T_\textit{id}$ can be written as:
\begin{equation} \label{eq:Tid} T_\textit{id} = O \operatorname*{arg\,max}_{\substack{i=1,\ldots,M\\ j=1,\ldots,N\\ k=1,\ldots,K}} \left \{ \frac{\alpha_\textit{HNi}}{f_\textit{CC}} , \frac{\alpha_\textit{CLj}}{f_\textit{CLj}} , \frac{\alpha_\textit{MDk}}{f_\textit{MDk}} \right \} \tag{4.8} \end{equation}$E_\textit{RSMD}$ can be defined as the sum of the energy spent to perform locally part of the task, $E_\textit{l}$, plus the energy spent to transmit data to the clouds, $E_\textit{tr}$, plus the energy spent during the idle period, $E_\textit{id}$, waiting for the computation performed outside and the results transmitted back:
\begin{equation} \label{eq:energyRSMD} E_\textit{RSMD} = E_\textit{l} + E_\textit{tr} + E_\textit{id} \tag{4.9} \end{equation}$E_\textit{l}$ is obtained by multiplying the \gls{RSMD}'s local computation power consumption, $P_l$, by the time consumed for computing locally the application:
\begin{equation} \label{eq:El} E_\textit{l}= P_l \frac{\alpha_0 O }{f_l} \tag{4.10} \end{equation}$E_\textit{tr}$ is determined by the power consumption of the RSMD for transmitting, $P_\textit{tr}$, multiplied by the transferring time. Thus we can write:
\begin{equation} \label{eq:Etr} E_\textit{tr} = P_\textit{tr} D \cdot \left ( \sum_{i=1}^\textit{M}\frac{\beta_\textit{HNi}}{\eta_\textit{HNi}} + \sum_{i=1}^\textit{N}\frac{\beta_\textit{CLi}}{\eta_\textit{CLi}}+ \sum_{i=1}^\textit{K}\frac{\beta_\textit{MDi}}{\eta_\textit{MDi}} \right ) \tag{4.11} \end{equation}$E_\textit{id}$ corresponds to the idle time $T_\textit{id}$, thus, taking into account the same considerations used for $T_\textit{id}$, we can write the following:
\begin{equation} \label{eq:Eid} E_\textit{id} = P_\textit{id} O \operatorname*{arg\,max}_{\substack{i=1,\ldots,M\\ j=1,\ldots,N\\ k=1,\ldots,K}} \left \{ \frac{\alpha_\textit{HNi}}{f_\textit{CC}} , \frac{\alpha_\textit{CLj}}{f_\textit{CLj}} , \frac{\alpha_\textit{MDk}}{f_\textit{MDk}} \right \} \tag{4.12} \end{equation}Thus, the optimization model consists in finding the values $\alpha_\textit{Xi}$ and $\beta_\textit{Xi}$ that minimize the equation \eqref{eq:latency-energy2}, by taking into account the relationships defined in equations \eqref{eq:throughput4}, \eqref{eq:shannon4}, \eqref{eq:latencyRSMD}, \eqref{eq:Tl}, \eqref{eq:Ttr}, \eqref{eq:Tid}, \eqref{eq:energyRSMD}, \eqref{eq:El}, \eqref{eq:Etr}, and \eqref{eq:Eid}. The model constraints are derived from the observation that the sum of the offloaded fractions must be equal to 1, thus the optimization problem becomes:
\begin{equation} \label{eq:optim-model} \underset{\alpha_\textit{Xi},\beta_\textit{Xi}}{\text{minimize}}\left\{w_E \frac{E_\textit{RSMD}(\alpha_\textit{Xi},\beta_\textit{Xi})}{E_o} + w_T \frac{T_\textit{RSMD}(\alpha_\textit{Xi},\beta_\textit{Xi})}{T_o}\right\} \tag{4.13a} \end{equation} \begin{equation} \text{s.t. } \;\; \alpha_0 + \sum_{i=1}^\textit{M} \alpha_\textit{HNi} + \sum_{i=1}^\textit{N} \alpha_\textit{CLi} + \sum_{i=1}^\textit{K} \alpha_\textit{MDi}= 1 \tag{4.13b} \end{equation} \begin{equation} \sum_{i=1}^\textit{M} \beta_\textit{HNi} + \sum_{i=1}^\textit{N} \beta_\textit{CLi} + \sum_{i=1}^\textit{K} \beta_\textit{MDi}= 1 \tag{4.13c} \end{equation}The obtained minimization problem cannot easy solved, so that, in the following section, we will resort to a sub-optimal solution based on a clusterization approach.
Cluster based optimization
The idea is to divide the urban area in subareas having range $r$; each SMD can share resources only with the other SMDs, cloudlets, and HetNet access points placed in the same subarea. This approach, even if sub-optimal, can simplify the problem by reducing the amount of concurrent devices that are involved in the computation offloading. This means, on the other hand, that we have to select the most appropriate cluster size.
If we define with $M_r$, $N_r$ and $K_r$, the number of HetNet access points, cloudlets and SMDs, respectively, within the cluster having range $r$, it is possible to write the transferring time needed by a single RSMD as:
\begin{equation} \label{eq:Ttr-r} T_{\textit{tr},r} = D \left ( \sum_{i=1}^{M_r}\frac{\beta_\textit{HNi}}{\eta_\textit{HNi}} + \sum_{i=1}^{N_r}\frac{\beta_\textit{CLi}}{\eta_\textit{CLi}}+ \sum_{i=1}^{K_r}\frac{\beta_\textit{MDi}}{\eta_\textit{MDi}} \right ) \tag{4.14} \end{equation}Let us suppose that among the $K_r$ SMDs within a cluster, $\bar{K}_r \leq K_r$ have an active task to be computed that can be offloaded to the surrounding nodes. Without going into the details of a scheduling algorithm to be used by the cluster based SMDs, we suppose that the $Apps$ are computed by all the SMDs that act as a pool of resources, by exploiting a RAN as a Service (RANaaS) cloud model [48]. In this case it is possible to calculate the overall transferring time as:
\begin{equation} \label{T_tr_tot} T^{\text{tot}}_{\textit{tr},r} = \sum_{j=0}^{\bar{K}_r}\sum_{i=1}^{M_r}\frac{D_j\beta_\textit{HNi}}{\eta_\textit{HNi}} +\sum_{j=0}^{\bar{K}_r} \sum_{i=1}^{N_r}\frac{D_j\beta_\textit{CLi}}{\eta_\textit{CLi}} + \frac{\sum_{j=0}^{\bar{K}_r}\sum_{i=1}^{K_r}D_j\beta_\textit{MDi}}{\sum_{i=1}^{K_r}\eta_\textit{MDi}} \tag{4.15} \end{equation}where $D_j$ is the amount of $App$ data requested by the $j^{th}$ RSMD. Similarly, it is possible to write the overall energy needed by the $\bar{K}_r$ nodes for offloading the task as:
\begin{equation} \label{E_tr_tot} E^{\text{tot}}_{\textit{tr},r} = \sum_{j=0}^{\bar{K}_r}\sum_{i=1}^{M_r}\frac{P_{tr,j}D_j\beta_\textit{HNi}}{\eta_\textit{HNi}} +\sum_{j=0}^{\bar{K}_r} \sum_{i=1}^{N_r}\frac{P_{tr,j}D_j\beta_\textit{CLi}}{\eta_\textit{CLi}} + \frac{\sum_{j=0}^{\bar{K}_r}\sum_{i=1}^{K_r}P_{tr,j}D_j\beta_\textit{MDi}}{\sum_{i=1}^{K_r}\eta_\textit{MDi}} \tag{4.16} \end{equation}From equations \eqref{T_tr_tot} and \eqref{E_tr_tot}, it is possible to observe that the transferring time related to the offloading within the SMD cluster is proportional to the square of the number of the SMDs, i.e., $T_\textit{tr,r},E_\textit{tr,r} \propto~K_r^2$, whereas it is linearly proportional to the number of SMDs in case only the centralized cloud or the cloudlets are used, i.e., $T_\textit{tr,r}, E_\textit{tr,r} \propto~K_r$; hence, it is possible to state that there is an optimal number of devices ${K}^o_{r}$ within a cluster such that, for $K_r\le{K}^o_{r}$ the offloading towards the centralized cloud is the optimal solution, whereas for $K_{r}>{K}^o_{r}$ the best performance is obtained for the distributed cloud. This means that the cluster size affects the optimization problem.
Since the numbers of SMDs affect primarily the transferring time and energy consumption, we focus our attention on their behaviour, without focusing on the idle and local time and energy consumption. Hence, the optimization problem in \eqref{eq:optim-model}, can be rewritten as:
\begin{equation} \label{eq:optim-modelKr} \underset{r}{\text{minimize}} \left\{w_E \frac{E^{\text{tot}}_{\textit{tr},r}(r)}{E_o} + w_T \frac{T^{\text{tot}}_{\textit{tr},r}(r)}{T_o}\right\} \tag{4.17} \end{equation}where the aim is to minimize the linear combination of latency and energy consumption by selecting the cluster size $r_o$ that contains the optimal number of devices ${K}^o_{r}$: this corresponds to estimate the density of the surrounding nodes and select the cluster size by comparing their amount with the optimal number. It is worth to be noticed that the density estimation of a distributed network has been studied in the literature by resorting to specific algorithms, such as in [49]. Hence, for a given scenario, once estimated the SMDs density, it is possible to set the cluster size based on ${K}^o_{r}$.
Once set the cluster size, with respect to the offloading problem, if $K_r\le{K}^o_{r}$, it is convenient to set $\sum_{i=1}^{M_r}{\alpha_\textit{HNi}}=1$ and $\sum_{i=1}^{M_r}\beta_\textit{HNi}$=1, that corresponds to a complete offloading towards the centralized cloud, whereas it is better to perform the offloading towards the nodes in the cluster for $K_r>{K}^o_{r}$. In this case we consider $\alpha_\textit{CLi} =\beta_\textit{CLi}$ and $\alpha_\textit{MDi}=\beta_\textit{MDi} $ for every node of the distributed cloud, since it is reasonable that the amount of processed data is proportional to the computation load; furthermore, we choose $\alpha_\textit{CLi}$ and $\alpha_\textit{MDi}$ s.t. $\alpha_\textit{CLi}/f_\textit{CLi} = \alpha_\textit{MDi} / f_\textit{MDi}$ for every node, since this is the value that minimize equation \eqref{eq:Tid} and, hence, equation \eqref{eq:latencyRSMD}.
Numerical Results
In order to prove the effectiveness of the proposed approach, we resort to a typical scenario for an Intelligent Trasportation System (ITS) proposed by Yu et al. [20], composed by the three-layered hierarchical cloud architecture for vehicular networks where the SMDs exploit cloud resources and services in an environment composed by vehicular clouds (i.e., the distributed topology), a set of roadside cloudlets, and a centralized cloud (see Fig. 4.1).

All the devices are supposed to be connected for improving transportation safety, relieve traffic congestion, reduce air pollution and enhance comfort of driving. The selected real-time application, unlike a traditional navigation - which only provides static geographic maps - could be able to offer dynamic three-dimensional maps and adaptively optimize routes based on traffic data mining. Thus, the computational time requirement is of utmost importance. On the other hand, considering that the great part of the involved mobile devices can be recharged directly from the cars in which they are placed, they do not need a restrictive energy consumption requirement. Due to these considerations, we focused the optimization problem for this scenario on a sub-optimal solution minimizing $T_\textit{RSMD}$, i.e. we consider the weight coefficients $w_E = 0$ and $w_T = 1$ and we assumed that all the devices are requesting the same application. Also the storage requirement could be neglected, while we established that the number of operations $O$ to be executed is equal to $10^6$ flops and the amount of exchanged data $D$ by each $App$ is equal to 0.5 Mbit.
In our scenario we considered a linear road 1000 m long with the presence of one centralized cloud with a computation rate $f_\textit{CC}$ equal to $10^3$ Gflops, obtained by an Amazon EC2 Cluster GPU instance, through a unique Proxim Tsunami MP 8250 Base Station Unit 4G placed in the middle of the road (at point 500), with a channel capacity equal to 300 Mbps.
A set of four roadside units are the cloudlets evenly positioned at the relative positions of 125, 375, 625, 875 m respectively. Every cloudlet is a compute-box using Nvidia GT520 GPUs with a computing capability $f_\textit{cl}$ equal to 150 Gflops [50]. The offered throughput of the cloudlet $\eta_\textit{cl}$ is 40 Mbps (considering one LTE cloudlet-devices link), with a coverage range $r_{\text{cl}}$ equal to 250 m, so that each cloudlet covers only a limited part of the road.
The SMDs are placed along the route with a uniform distribution, simulating a road where a fluent traffic is present. The SMD computational speed $f_\textit{dev}$ is equal to 10 Gflops, while their offered throughput $\eta_{dev}$ is equal to 10 Mbps - considering to use the IEEE 802.11p vehicle-to-vehicle standard - and a reference SNR equal to 30 dB. We considered also, for the energy evaluation, the parameters of an HP iPAQ PDA with $P_l$ equal to 0.9 W, $P_{\textit{id}}$ equal to 0.3 W, $P_{\textit{tr}}$ equal to 1.3 W.
We have chosen different cases for partitioning the subareas of the distributed clouds, with ranges equal to 250 m, 50 m, 25 m, and 10 m, where every SMD can share resources with the other SMDs placed in the same subarea.
In Fig. 4.2 the performance in terms of average latency for an increasing number of SMDs by comparing the total offloading towards the centralized cloud and the distributed clouds is depicted. Four possible clusterizations for the distributed cloud infrastructure are considered; furthermore the total offloading to the nearest cloudlet is also considered. These are compared with the local computation as a benchmark. Moreover, the optimal solution is reported, where the range is selected based on the SMD density.

It is possible to see that by varying the number of SMDs inside the considered area, the most efficient CCIs, to which is convenient to offload, change. In particular for a low density of SMDs it is convenient to offload towards the centralized cloud, corresponding to set the cluster range to infinity, while the cloudlets are convenient just over. This is because in case of low density the SMDs are isolated and, moreover, their communications through the eNodeB -i.e., centralized cloud or cloudlets- have a limited intra-system interference. However, when the number of SMDs increases it is possible to see that the use of the distributed cloud become more convenient, with the cluster size reducing with the increasing of the SMDs. The optimal solution allows to select the best cluster range based on different density situations by approaching always the best cluster size. It is worth to be noticed that the optimal number of SMDs $K^o_r$, in this case, is equal to 50.
In Fig. 4.3 the average energy consumption is depicted by considering a variable number of SMDs, and considering the same cluster sizes as in Fig. 4.2. Even if the energy issue does not affect the operations of this particular scenario, where all SMDs are supposed to have unlimited energy since reloaded by the cars' resources, we can consider this issue from an echo-friendly point of view. Comparing the trends of the consumed average energy in the various cases, it is undeniable that the clusterization allows to reduce the consumed energy in case of high traffic scenarios as those present in a smart city environment, and the optimal solution allows to select for different populations the best cluster size, and offloading policy.

Finally, in Fig. 4.4 the performance in terms of throughput is shown by comparing the distributed cloud infrastructure with 10 m of range, the total offloading toward the central cloud and the nearest cloudlet and the optimal solution. It is possible to note that the distributed offloading technique outperform the other techniques, except in case of low density of the nodes.
Conclusions
In this chapter an optimization model for supporting the computation offloading in the UMCC is conceived in a particular IoT scenario, where the objects, consisting of different CCI, can interact through different types of wireless connections, for creating a distributed computing environment. The distributed computing resource allocation results to be a complex problem due to the presence of several devices and possible wireless connections, thus, we resort to decreasing its complexity by considering a clustering approach for the resource sharing, observing that the use of cluster offloading is useful especially for high density SMD distribution. The numerical results, based on a scenario performing a real-time navigation application of with computation resource sharing, confirm the advantages of the clusterization especially in dense scenarios.
Part III - Optimization Considering a Considering a Community of Devices
In a typical smart city ecosystem, where a great affluence of mobile devices try to perform applications at the same time, a competition for allocating remote resources occurs, becoming a potential cause of delay and energy consumption. In such a large-scale and dynamic system, relevant optimization challenges concerning the operational assignment of computation offloading become a community issue. Most of these challenges are related to the minimization of the necessary time and energy employed for satisfying the mobile users' requests.
In this part of the thesis the problem of CA in a UMCC framework is analized, considering the system as a community, thinking about the improvement of the collective performance and not only the one of a single device. In chapter 5 three different methods for solving the offloading-related CA problem are compared: the first leads to the optimal solution, but it requires the complete information about the final position of the requesting devices and, therefore, cannot be used in a realistic scenario with online demands. The other two get sub-optimal solutions, but allow connecting each device on the fly - as new requests appear. The first of these two online algorithms is based on a greedy heuristic which chooses 'the best' network node for each single device - selfish behaviour. The second one is a probabilistic algorithm that makes use of biased-randomization techniques [51] in order to enhance the quality of the solution from a social or collective point of view.
The content of the following chapter was extracted from publications [P2] and [P4].
5. A Social-Aware Biased-Randomized Algorithm for UMCC
Introduction
In this chapter the UMCC is exploited for accomplishing applications in a cooperative way while satisfying the QoS requirements for the citizens involved. By taking into account all users in the assignment process, the proposed biased-randomized algorithm allows to enhance social-aware performance as compared with the greedy approach while, at the same time, it allows for online allocation of resources.
Although the computation offloading can significantly increase data processing capability for the single mobile users, it is challenging to achieve an efficient coordination among the entire set of requesting devices when the environment is particularly crowded. In fact, the computation offloading entails data transmission among the devices and the cloud, to make the operation possible. If a great number of users utilize the same wireless resource to delegate computation to the cloud, this operation can affect the efficiency of the access node, since its channel capacity has to be shared among all the devices, causing a reduction of the throughput experienced by each user. This can lead to a crucial use of energy and time spent for data transmission, making not convenient the offloading operation [41].
In this chapter we present a probabilistic method that makes use of biased-randomization techniques to solve the CA problem, i.e. to select, among the available access nodes, the one that increases the system efficiency. This method is compared with the global optimization solution, that is shown to be unacceptable from a point of view of time computation, and with a greedy algorithm [52], that instead implement a selfish behaviour in allocating the resources to the users. All the three techniques - the probabilistic, the greedy and the optimal - are based on the definition of a proper cost function that takes into account the different requirements and characteristics of the considered UMCC framework. We will consider, for our example and calculation, the throughput, the energy consumption, and the delay as those parameters that drives the optimal allocation of the resources to be offloaded.
The novel proposed algorithm improves the solutions and is easy to implement in real time, thus outperforming by far the solutions provided by the heuristic approach. The underlying biased randomization techniques [51] introduces some degree of randomness using a skewed probability distribution and reaching a solution nearer to the optimal without the need of knowing all the SMDs' positions.
As it will be illustrated in the numerical results, the use of the biased-randomized approach allows to easily enhance the quality of the solutions generated by the original heuristic in different dimensions when considering social or collective performance. It is important to notice that if a uniform probability distribution would be used instead of a skewed one, this improvement would very rarely occur since the logic behind the constructive heuristic would be destroyed and, accordingly, the process would be random but not correctly oriented.
In the context of combinatorial optimization problems, constructive heuristics use an iterative process in order to construct a `good' and feasible solution. Examples of these heuristics are the savings procedure for the Vehicle Routing Problem [53], the NEH procedure for the Flow-Shop Problem [54], or the Path Scanning procedure for the Arc Routing Problem [55]. In all these heuristics, a `priority' list of potential movements is traversed during the iterative process. At each iteration, the next constructive movement is selected from this list, which is sorted according to some criteria. The criteria employed to sort the list depends upon the specific optimization problem being considered. Therefore, a constructive heuristic is nothing more than an iterative greedy procedure, which constructs a feasible `good' solution to the problem at hand by selecting, at each iteration, the `best' option from a list, sorted according to some logical criterion. Notice that this is a deterministic process, since once the criterion has been defined, it provides a unique order for the list of potential movements. Of course, if we randomize the order in which the elements of the list are selected, then a different output is likely to occur each time the entire procedure is executed. However, a uniform randomization of that list will basically destroy the logic behind the greedy behaviour of the heuristic and, therefore, the output of the randomized algorithm is unlikely to provide a good solution.
Problem Description
The environment consists of a urban area with a pervasive wireless coverage, where several mobile devices are interacting with a centralized cloud infrastructure and request for services from a remote data center. In order to connect the SMDs to the cloud, the presence of different types of RATs that compose the basic elements of the HetNet has been considered. The SMDs can connect to the cloud, as shown in Figure 5.1, by using the reachable RATs. The selection will depend upon the distance to the RATs as well as on other features that will be detailed below.

The existence of different RATs allows cloud computing systems to complement the resource-constrained mobile devices. In effect, storage and computing tasks can be completed in the cloud, where the appropriate technology is selected among a variety of options. Different strategies can be carried out in order to enhance the network capacity, such as: deployment of relays, distributed antennas, and small cellular base stations (e.g. macrocells, picocells, femtocells), etc. These deployments have occurred indoors, in residential homes and offices, as well as outdoors, in amusement parks and busy intersections.
These new network deployments are typically comprised by a mix of low-power nodes underlying the conventional homogeneous macrocell network. By deploying additional small cells within the local-area range and bringing the network closer to users, they can significantly boost the overall network capacity through a better spatial resource reuse. Inspired by the attractive features and the potential advantages of HetNets, their development have gained much momentum in the wireless industry and research communities during the past few years.
The goal of the system and of every SMDs, indeed, is to choose and exploit effectively the different available RATs for transmitting the application data and for offloading towards the cloud. However, if this operation is not convenient, the application can be computed locally by the requesting SMDs. The analized approaches to solve a collective CA problem are based on a cost function related to the number and the localization of the SMDs. The first approach is the optimization of the cost function, considering a relation among the different measures involved, but it can only be used once the position and requests of all the SMDs is known {i.e., it cannot be used for online allocation of resources. Thus, this approach assumes that all users' requests are processed at the same time (or, alternatively, that the allocation decision is postponed until all requests have been received, which, in practice, might require customers to wait for their requests to be served.
The second approach adopts a heuristic method that makes use of a `greedy' behavior consisting on the selection of the `best next step' from a list of potential constructive movements [47], allowing to find a good solution on the fly, so that every SMD can connect to the proper cell without waiting for all the other SMDs taking place in the environment.
The third, finally, is a novel algorithm that makes use of biased-randomization techniques [48] to improve the results obtained with the second.
In the base heuristic described for the second algorithm, each agent tries to make the choice that maximizes his/her individual utility function. However, this might lead to sub-optimal solutions from a collective or social point of view, since individual decisions do not take into account a global perspective.
In this context, the main idea behind our third approach is to introduce a slight modification in the greedy constructive behavior. This is done such in a way that the constructive process is still based on the heuristic logic but, at the same time, some degree of randomness is introduced. This random effect is generated throughout the use of a skewed probability distribution: at each step of the constructive process, each potential movement receives a probability of being selected, being this probability higher as more `promising' the movement is.
In the following of this section the various components of the UMCC described in chapter 1 are recalled emphasizing the dependency from the parameters that play a role in the used algorithms.
Centralized Cloud
The cloud entity Ccc is characterized by its own computation speed, fcc. The storage availability of Ccc can be considered infinite, and thus it does not represent a constraint in the interaction with the SMDs. Hence, for the centralized cloud it is possible to write:
\begin{equation} C_{\textit{cc}} = C_{\textit{cc}}(f_{\textit{cc}}) \end{equation}HetNet nodes
The wireless HetNet infrastructure is composed of some RAT nodes, each of them characterized by different features:
- Channel Capacity $BW$: the nominal bandwidth of a certain communication technology that is available for the requesting connecting devices;
- $n$: the number of devices connected to the RAT;
- $posRAT(x; y)$: the position in which the RAT is located.
Hence, for the a generic RAT it is possible to write:
\begin{equation} \label{RAT-5} \textit{RAT} = \textit{RAT}(\textit{BW}, n, pos_\textit{RAT}(x,y)) \end{equation}Applications
Even if every SMD of the system can simultaneously request the computation offoading of one or more applications, we focus on a scenario where each SMD demand is restricted to a single application, which is characterized by the number of operations to be executed, $O$, and the amount of data to be exchanged, $D$. This simplification does not prevent the generalization of the system, since the general case in which a user requests several applications at a given time can be seen as an aggregation of several single-application requests. Hence, it is possible to express a generic application $App$ as:
\begin{equation} \label{App-5} \textit{App} = \textit{App}(O,D) \end{equation}SMDs
Each SMD is characterized by the following features which infuence the performance of the computation offloading:
- $P_\textit{tr}$: the power consumed by the SMD to transmit data to the node
- $P_l$: the power consumed by the SMD for local computation
- $P_\textit{id}$: the power consumed by the SMD in waiting mode while the computation in performed in the cloud
- $f_\textit{md}$: the speed to perform the computation locally
- $\textit{SNR}$: the SNR of the device
- $pos_\textit{md}(x,y)$: the position in which the SMD is located.
Hence, for a generic smart mobile device SMD:
\begin{equation} \label{SMD-5} \textit{SMD} = \textit{SMD}(P_\textit{tr},P_l,P_\textit{id},f_\textit{md},\textit{SNR}, pos_\textit{md}(x,y)) \end{equation}Given these entities, with the respective features, and defining $d_\textit{i,j}$ as the distance between the $i$-th RAT to the $j$-th SMD, we can resort the Shannon formula for the throughput $S_\textit{i,j}$ delivered by the $i$-th RAT to the $j$-th SMD, where $k$ is an attenuation coefficient for the signal propagation:
\begin{equation} \label{eq:distance-5} d_\textit{i,j} = \left|pos_\textit{RAT,i}(x,y)-pos_\textit{md,j}(x,y)\right| \end{equation} \begin{equation} \label{eq:throughput-5} S_\textit{i,j} = \frac{\textit{BW}_i}{n_i}\log_2\left\{1+\textit{SNR}_j e^{-k d_\textit{i,j}} \right\} \end{equation}In case of computation offloading, Equation \eqref{eq:throughput-5} affects both the measures we are considering for evaluating the QoS:
- the energy consumed by the $j$-th SMD, i.e.: the sum of the energy spent in transmitting the application data plus the energy consumed while the application is computed on the cloud server;
- the time required to accomplish the application, i.e.: the sum of the time spent in transmitting the application data plus the time for computation on the cloud server.
Considering an overall number of $N$ devices and a total number of $M$ HetNet nodes, the energy and the time spent by the $j$-th SMD for offloading towards the $i$-th RAT are, respectively:
\begin{equation} \label{eq:energyOD-5} E_\textit{i,j} = \frac{P_\textit{tr i}\,D}{S_\textit{i,j}} + \frac{P_{id\,i}\,O }{f_{cc}} \quad i=1,2,\dots,M;j=1,2,\dots,N; \end{equation} \begin{equation} \label{eq:timeOD-5} T_\textit{i,j} = \frac{D}{S_\textit{i,j}} + \frac{O}{f_{cc}} \quad i=1,2,\dots,M;j=1,2,\dots,N; \end{equation}On the other hand, in case of local computation executed by the $j$-th SMD, the energy and the time consumed by the SMD are, respectively:
\begin{equation} \label{eq:energyL-5} E_\textit{0,j}=\frac{P_{l\,j}\,O}{f_\textit{md\,j}} \quad j=1,2,\dots,N; \end{equation} \begin{equation} \label{eq:timeL-5} T_\textit{0,j} = \frac{O}{f_\textit{md\,j}} \quad j=1,2,\dots,N; \end{equation}where the 0 index represents a fictitious node related to this operation.
The SMD requesting to compute an application $App$ evaluates if the computation offloading is convenient and which is the RAT to be used. The decision aims at minimizing the energy consumption of the user requesting the service as well as the execution time required to accomplish the application. Therefore, the decision is `selfish' in the sense that it does not take into account the current and future needs of other users.
We consider, instead, to optimize the global energy consumption, assuming an environment where the devices of the set ${\cal{N}} = \{ 1, 2, \cdots, j, \cdots, \textit{N} \}$ are requesting to offload an application using the nodes of the set ${\cal{M}} = \{ 0, 1, 2, \cdots, i, \cdots, \textit{M} \}$, where the 0-th element represents the fictitious node related to the local computation.
Defining $x_{i,j}$ as a binary variable that indicates whether SMD$_j$ is assigned to RAT$_i$ or not, and $y_j$ as another binary variable to account for SMD$_j$ computing locally its application, it is possible to write the energy consumed by SMD$_j$ when offloading towards RAT$_i$ (Equation \eqref{eq:energyOD-5}) by exploiting Equation \eqref{eq:throughput-5}
\begin{equation} \label{eq:energyFunctionCost-5} E_\textit{i,j} = x_{i,j}\left(\frac{P_\textit{tr j}\,D}{\frac{\textit{BW}_i}{n_i}log_2\left\{1+\textit{SNR}_j e^{-k d_\textit{i,j}} \right\}} + \frac{P_\textit{id\,j}\,O }{f_{cc}}\right) + y_j \left( \frac{P_{l\,j}\,O}{f_\textit{md\,j}} \right) \end{equation} \begin{equation*} x_{i,j} = \begin{cases} 1& \text{if SMD$_j$ is assigned to RAT$_i$},\\ 0& \text{otherwise}. \end{cases} \end{equation*} \begin{equation*} y_j = \begin{cases} 1& \text{if SMD$_j$ computes $App$ locally},\\ 0& \text{otherwise}. \end{cases} \end{equation*}where $n_i$ is the number of SMDs connected to RAT$_i$, i.e. $n_i = \sum_{l \in \cal{N}} x_{i,l}$.
Rearranging the constant terms and the variable terms it is possible to write:
\begin{equation} E_{i,j} = x_{i,j} \left\{ K^\textit{tr}_{i,j} \sum_{l \in \cal{N}} x_{i,l} + K^{id}_j \right\} + y_j E_{0,j} \label{eq:energyODmodel-5} \end{equation}The constant part for offloading due to the transmission is computed as $K^\textit{tr}_{i,j} = \frac{P_\textit{tr j}\,D}{\textit{BW}_ilog_2\left\{1+\textit{SNR}_j e^{-k d_\textit{i,j}} \right\}}$ plus the constant part $ K^{id}_j = \frac{P_{id\,j}\,O }{f_{cc}}$. Therefore the optimization model can be expressed as:
\begin{equation} \min_{x,y} Z = \sum_{\substack{ i \in \cal{M} \\ j \in \cal{N}}} x_{i,j} \left\{ K^{tr}_{i,j} \sum_{l \in \cal{N}} x_{i,l} + K^{id}_j \right\} + \sum_{j \in \cal{N}} y_j E_{0,j} \label{eq:mod_minEnergy-5} \end{equation} \begin{equation*} s.t. \sum_{i \in \cal{M}} x_{i,j} + y_j = 1 \qquad\qquad j \in \cal{N} \end{equation*} \begin{equation*} x_{i,j}, y_j \in \{0,1\} \qquad\qquad i \in \cal{M} \qquad \textit{j} \in \cal{N}; \end{equation*}The objective function (\eqref{eq:mod_minEnergy-5}) minimizes the overall energy spent, while ensuring that all devices are either assigned to a RAT or leaving the computations to be done locally.
5.3 Optimal and Heuristic Solutions
In this section different methods to solve the optimization model are presented. A first approach is to use an off-the-shelf commercial solver, but for real large-size instances it requires unsuitable computation times. Moreover, since we take into account mobile SMDs, thus their position changes in time, the cell association has to be computed often. Therefore, given that the assignation of the SMDs to the RAT nodes has to be done in a very short time, we analyze several heuristic procedures. We focus on a novel \autoref{algo:BRAalgo} based on biased randomization strategy, that is proposed to improve the quality of the solution from a social or collective point of view, enhancing a previously proposed greedy \autoref{algo:ACalgo}. To evaluate their effectiveness we use the optimal solution presented in \autoref{sub:model}, that can only be applied \emph{ex-post}, once all the SMD requests have been revealed. This optimal solution is found using the procedure of \autoref{algo:Baronalgo}. In particular, since the global optimization needs to know the position and the requests of all the SMDs, it cannot be used for online allocation of resources. Thus, this approach assumes that all users' requests are processed at the same time --or, alternatively, that the allocation decision is postponed until all requests have been received--, which in practice might require customers to wait for their requests to be served.
On the other hand, the heuristic method making use of a `greedy' behavior, consisting on the selection of the `best next step' from a list of potential constructive movements \cite{Globecom2014}, allows to find a good solution in real time, so that every SMD can connect to the proper cell without waiting for all the other SMDs taking place in the environment. But with this heuristic, each agent tries to make the choice that maximizes his/her individual utility function, so that this might lead to sub-optimal solutions from a collective or social point of view, since individual decisions do not take into account a global perspective.
Optimal Solution
The previous objective function shown in \autoref{mod:assignmentModel-5} can be seen as an application of the QSAP which is NP-hard \cite{burkard-2013}. A first approach to find the solution is to use the global optimizer Baron \cite{Baron}. The Branch-And-Reduce Optimization Navigator derives its name from its combining constraint propagation, interval analysis, and duality in its reduce arsenal with advanced branch-and-bound optimization concepts.
Note that the QSAP not only needs to know the position of all SMDs requests before assigning them to an antenna, but also it takes a time longer than the needed to serve quickly the SMDs, as shown in \autoref{sec:numerical-results-5}. Therefore, the optimal resolver can be taken only as reference, to compare fast heuristics (which can do the assignation dynamically or with a \emph{wait-and-go}) with an optimal, ideal solution.

The Greedy Heuristic
In this sub-section, we recall a heuristic algorithm used to solve the CA problem following a greedy behavior. It has been used also in \autoref{chap:GLOBECOM14}, to resolve the CA problem in the case discussed above, considering a user-satisfaction based utility function. If the offloading operation is advantageous with respect to the local computation, the CA scheme leads to select the `best' next node from the list of the available ones. The requests of the SMDs appear in time sequence, and the cost function is evaluated on the basis of the current situation, i.e., considering only the previously appeared SMDs. If the offloading cost is less than the cost for the local computation, the SMD will connect to the node which minimizes the cost function, otherwise it will compute the application without connecting. The selection of the $i$-th node for connecting the $j$-th SMD modifies the values of the throughput $S_\textit{i,k}$ and consequently of the energy $E_\textit{i,k}$ for the SMDs already connected with the same node, i.e., for $k=1,2,\dots,j-1$. Thus, this strategy, reported in \autoref{algo:ACalgo}, does not take into account any forecast of future connections, leading to a sub-optimization due to the randomness of the requests.

Biased-randomized Algorithm
Making use of biased-randomization techniques \cite{Juan2011}, the proposed probabilistic algorithm is able to find near-optimal solutions in real time, thus outperforming by far the solutions provided by the heuristic approach. The main idea behind our novel approach is to introduce a slight modification in the greedy constructive behavior. This is done in such a way that the constructive process is still based on the heuristic logic but, at the same time, a certain degree of randomness is introduced. This random effect is generated throughout the use of a skewed probability distribution: at each step of the constructive process, each potential movement receives a probability of being selected, being this probability higher for the more \emph{promising} movements.
As it will be illustrated in the numerical results, the use of the biased-randomized approach allows to easily enhance the quality of the solutions generated by the original heuristic in different dimensions when considering social or collective performance, reaching a solution nearer to the optimal, without the need to know all the SMDs' positions.
Also, it is important to notice that if a uniform probability distribution would be used instead of a skewed one, this improvement would very rarely occur since the logic behind the constructive heuristic would be destroyed and, accordingly, the process would be random but not correctly oriented.
To avoid losing the logic behind the heuristic, GRASP meta-heuristics \cite{Feo1995} proposes to consider a restricted list of candidates --i.e., a sub-list including just some of the most promising movements, that is, the ones at the top of the list--, and then apply a uniform randomization in the order the elements of that restricted list are selected. This way, a deterministic procedure is transformed into a randomized algorithm --which can be encapsulated into a multi-start process--, while most of the logic or common sense behind the original heuristic is still respected.
The proposed biased-randomization approach goes one step further, and instead of restricting the list of candidates, it assigns different probabilities of being selected to each potential movement in the sorted list. In this way, the elements at the top of the list receive more probabilities of being selected than those at the bottom of the list, but potentially all elements could be selected. Notice that by doing so, we are not only avoiding the issue of selecting the proper size of the restricted list, but we also guarantee that the probabilities of being selected are always proportional to the position of each element in the list. As a result, each time the randomized algorithm is executed, a new probabilistic solution is obtained (\autoref{fig:Scheme}). Some of these solutions will improve the original one provided by the base heuristic and, moreover, the proposed approach allows to offer alternative solutions to choose from, each of them with different properties.
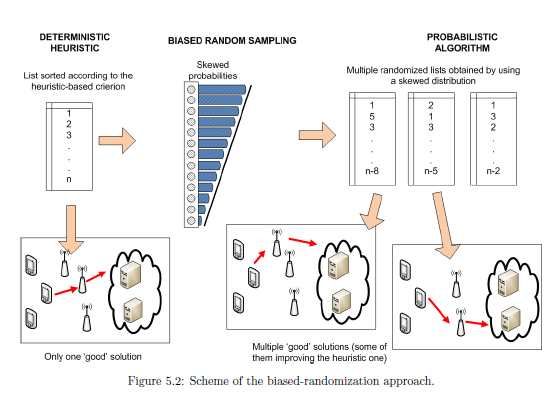
Focusing on our specific problem, the biased-randomization algorithm for the cell association consists of a skewed criteria based on the same cost function utilized for the greedy heuristic, i.e., the SMD's energy consumption for computing the application. When a SMD request occurs, the cost function $E_\textit{i,j}$ is evaluated for every possible RAT node (considering also the fictitious node $0$ related to the local computation).
The values are sorted in a way so that the probabilities of being selected depend not only on the cost function $E_\textit{i,j}$, but also on the distances $d_\textit{i,j}$ of the device from the RAT nodes and on the number of devices $n_i$ that potentially can be connected to each RAT node.
In fact, on the basis of the greedy algorithm, a SMD far from all the RAT nodes, but occurred before any other, is associated to a RAT because the cost function value of the offloading is less than the cost function for the local computation. Instead, due to the high probability that another SMD closer to this RAT occurs, the local computation could be a better choice, giving place to the connection of the second closer SMD. To improve the cell association, the criteria for sorting the list of choices takes into account the product $d_\textit{i,j} \cdot E_\textit{i,j}$, with $i \in \{{0\}} \cup \mathcal{M}$, instead of $E_\textit{i,j}$. The value of $d_\textit{0,j}$ is adjusted empirically and depends on the overall number of SMDs which are expected to interact in the system. We selected a value $d_\textit{0,j}$ depending on the overall number of SMDs which are supposed to interact in the system. The value of $d_\textit{0,j}$ has been evaluated observing the optimal solution given by \ref{sub:model} in the post-analysis, i.e., when all the SMD positions are already known.
This strategy is reported in Algorithm \autoref{algo:BRAalgo}.

5.4 Numerical Results
We considered a deployment area similar to that of the previous chapters, i.e. an extension of $1000 m^2$, where one LTE eNodeB with channel capacity equal to 100 MHz is positioned at point (500, 500) and three WiFi access points with channel capacities equal to 22 MHz are positioned at point (0, 0), (500, 999) and (1000, 0). Each of them is supposed to cover the entire area and we considered an attenuation coefficient for the propagation $k$ equal to $10^{-3}$. Furthermore, similarly to \cite{Globecom2014}, the capacity constraints on the antennas is not considered, assuming there is no limitation on the number of customers.
The SMDs are placed in the deployment area according to a uniform distribution. In particular, we have chosen a controlled random number generation of type Mersenne Twister with seed equal to 1. The values of $f_{\textit{md}}$, $P_{\textit{id}}$, $P_{\textit{tr}}$, $P_l$, and $\textit{SNR}$ are specific parameters of the mobile devices. We considered the values of an HP iPAQ PDA with a 400 MHz Intel XScale processor ($f_{\textit{md}}=400$ MHz) and the following values: $P_l = 0.9 W$, $P_{\textit{id}} = 0.3 W$, $P_{\textit{tr}} = 1.3 W$, and $\textit{SNR} = 1000$. Regarding the cloud server, we suppose a computation speed $f_{cs} = 10^6$ MHz~\cite{Kumar}. We have chosen an application which is accomplished through a number of operation $O = 10^7$ and, if offloaded, needs a data transfer $D = 10^4$ bits.
We have compared the cell association configurations resulting from the greedy heuristic, the biased-randomization algorithm, and the Baron solution. The no-connections configuration (all the SMDs compute local) and the nearest-node configuration (each SMD connected to the closest RAT) are also taken into account for comparison. The throughput, the energy consumed by the SMDs and the time employed for accomplishing the application are evaluated and observed for each configuration, considering an increasing number of SMDs involved in the system, in particular 500, 1000, 2000, and 5000.
\autoref{tab:result_throughput}, \autoref{tab:result_energy}, and \autoref{tab:result_time} show, respectively, the results related to the throughput, the energy, and the time. The ex-post solution has been computed with Baron under the Neos server http://www.neos-server.org). The QSAP model is implemented with the mathematical modeling language GAMS. The other methods have been implemented in Matlab.

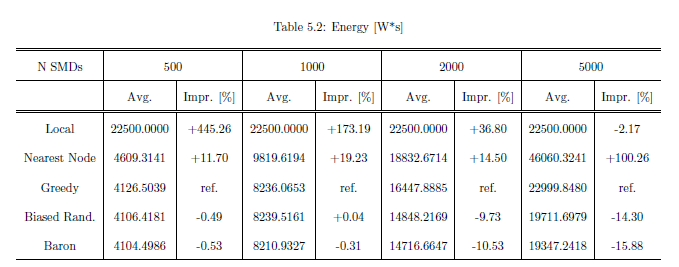
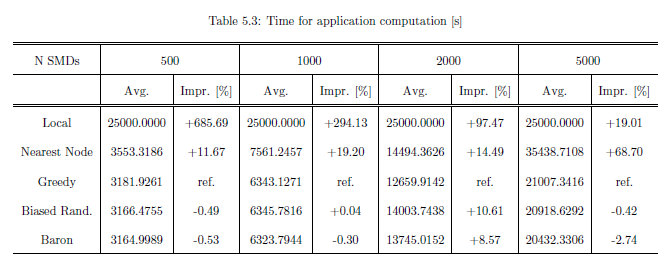
5.5 Analisys of Results
The results of \autoref{tab:result_throughput}, \autoref{tab:result_energy}, and \autoref{tab:result_time} show that the biased-randomized algorithm clearly improves the cell association configuration with respect to the greedy heuristic. These improvements are: 2.24\% in throughput, 14.30\% in energy consumption, and 0.42\% in computation time.
Also, the average energy and time values provided by the randomized algorithm, which only requires some milliseconds to compute, are quite similar to the solutions provided by Baron, which is stopped after 1,000 seconds of computation. The results are visually compared in \autoref{fig:throughputComparison} and in~\autoref{fig:throughput-5}, where we can see that the trends of average throughput are very similar, practically overlapped, in the three cases of interest, i.e. the greedy heuristic, the biased randomized algorithm, and the Baron ex-post configuration. This means that the capacity of the RAT nodes is well-exploited in all the three cases considered. In \autoref{fig:throughputComparison} the average throughput values are visualized in a different scale to make possible the comparison of the three algorithms.
Considering the average energy consumed by a SMD to perform the application, which is the objective function to minimize, Figure \autoref{fig:energy-5} shows that the biased-randomized algorithm clearly outperforms the greedy heuristic. The same observation can be inferred from Figure\autoref{fig:time-5} in relation to the average time that a device needs to accomplish the application. Both the average energy and the time values are very close to the respective Baron configuration average energy and time values, thus the biased randomized algorithm can be exploited by the SMDs to reach a near-optimal configuration in real time while the solution seen from a collective point of view minimizes the overall energy consumption. This is useful for offloading applications which need a fast cell association decision, for example when the users are in movement and the configuration must be updated very often.
Comparing the different configurations of the devices placed in the observed area, reported in \autoref{fig:scatter500}, \autoref{fig:scatter1000}, \autoref{fig:scatter2000} and \autoref{fig:scatter5000} for a total number of SMD equal to 500, 1000, 2000 and 5000 respectively, we can note that the case referring to the biased-randomized algorithm is very similar to the ex-post optimal solution, where the SMDs connected to the same RAT are clustered in the neighborhood of the RAT.
5.6 Conclusion
In this chapter we presented different strategies for efficient cell association in pervasive wireless environments. In particular, we proposed an original probabilistic algorithm that allows to consider a more global point of view --instead of just an individual one-- during the real-time resource allocation. Thus, the mobile communication system is managed in a cooperative way, considering the QoS of the entire population of mobile users. This vision could be adopted for the provision of services in a smart city, improving performance and well-being of the community through a social use of the UMCC framework. Our approach is based on the use of biased-randomization techniques, which have been used in the past to solve similar combinatorial optimization problems in the fields of logistics, transportation, and production. This work extends their use to the field of smart cities and mobile telecommunications. Some numerical experiments contribute to illustrate the potential of the proposed approach.
6. Conclusion and future works
6.1 Final Conclusions
The actual realization of the vision of smart cities is an exciting perspective with the potential of bringing tremendous improvements to our society, thanks to novel pervasive services assisting us in every aspect of our lives.
While the increasingly deep integration of ICT services in the physical world has been the main enabling factor motivating this vision, we believe that the intelligent and efficient exploitation of the infrastructures will be the key to its success.
Our contribution has proposed an original solution approach for dealing with common resources that need an optimization for the distribution among users.
We hope that our work was successful in proposing general and simple solution principles that can be used fruitfully as starting points for new research efforts toward the realization of future large scale smart pervasive environments. Finally, let us note that, while the scope of our research was focused on the specific application scenario of smart city environments, we believe that most of the presented results can be easily and successfully used in other scenarios with similar requirements of efficient and scalable distribution, such as the management of large scale telecommunication infrastructures or smart grids deployments.
6.2 Directions for Future Works
Cities around the globe are beginning to build out new digital services such as smart lighting, traffic, waste management and data analytics to reduce costs, tap new sources of revenue, create new innovation business districts and improve the overall quality of urban life. Integrated IoT and MCC applications enabling the creation of smart environments such as smart cities need to be able to combine services offered by multiple stakeholders and scale to support a large number of users in a reliable and decentralized manner. They deal with constraints such as access devices or data sources with limited power and unreliable connectivity. The UMCC needs to be enhanced to support a seamless execution of applications harnessing capabilities of multiple dynamic and heterogeneous resources to meet quality of service requirements of diverse users.
The management of distributes mobile platform resources need further investigation. This thesis is a starting point for a user-centric model that requires additional heterogeneity: i.e. customized needs and different QoS levels. For example, some users could not have problem of battery charge whereas others could need to save energy (i.e. SMD having a low-battery-level status). Thus, the clusterization debated in chapter 4 needs to be deeply investigated.
A further point of invetigation is the study of SMDs in motion, for analyzing the time evolution of the system: in chapter 5 the approach on the fly assigns a RAT node to a SMD every time a request occurs, but, since it depends on the position of the devices, the CA needs a time optimization subordinate to the speed of the devices.
In addition, considering an operational research perspective, the CA assignation in the UMCC can be seen as a stochastic allocation of resources, in particular an assignation of the SMDs to the available RATs, as shown in Fig. 6-1.

In fact, being mobile, the position of the devices change over time, and it is possible to assume that the position of each device in a future target time can be characterized by two random variables, describing the x and y location, respectively as shown in Fig. 6-2..

It will also be assumed that the expected value of each random variable will be given by the current position of the respective device. Assuming that the expected value of each random variable will be given by the current position of the respective device, it is possible to model this scenario as a FLP with stochastic assignment costs - i.e. a combination of different factors, such as time-based costs and energy-based costs, random variables proportional to the Euclidean distance between the device and the RAT node. It is worth to note that the RATs’ capacity could be considered either as virtually unlimited or not, thus leading to two different problems: the Uncapacitated FLP and the Capacitated FLP, respectively. One way to deal with these stochastic FLP would be to use a simheuristic approach [59] i.e., a combination between a fast metaheuristic - able to quickly generate several good or promising solutions for the deterministic version of the FLP - and a fast simulation process able to estimate the expected cost associated to a given deterministic solution when it is used for the stochastic scenario. The main goal of this future work will be to minimize the expected costs of the assignment process. The simulation, however, could also provide insights on the ‘robustness’ of each promising solution, enriching a risk analysis investigation.
Contents
List of Tables
ddd